関数とメソッド#
# 警告メッセージを非表示
import warnings
warnings.filterwarnings("ignore")
関数と引数#
コードを書くうえで関数は非常に重要な役割を果たすのが関数である。主に2つのタイプに分けることができる。
組み込み関数(最初から準備されている関数)
ユーザー定義の関数(ユーザー自身が作成する関数)
名前から想像できるが,プログラミングの関数は数学の関数と非常に似ている。数学の\(y=f(x)\)という関数を考えてみよう。より具体的に\(f(x)=x^2\)と置いてみよう。\(x\)は\(-\infty\)から\(\infty\)の実数を取ることができ,それらに対応する\(y\)の値が返される関数である。Pythonでも同じ関数を簡単に作ることができる。例えば,func(x)という関数だとしよう。Pythonでは次の用語を使う。
func:関数名x:引数
次に,実際に関数を実行し計算するためには\(x\)に値(例えば,2)を指定する必要がある。数学の関数\(f(x)\)であれば\(f(2)\)と置くが,Pythonの関数でも同様にfunc(2)と書き,4が返される。この場合,次の用語を使う。
引数値:引数に指定した値である
2
まとめると,引数とは関数を実行する前に定義することになり,引数値を指定することにより関数を実行することができる。
組み込み関数#
組み込み関数(built-in functions)とは,ユーザーが使えるように事前に準備された関数である。以下が既出の組込み関数である。
type():データ型を調べるint():整数型に変換float():不動小数点型に変換str():文字列型に変換bool():真偽値の確認list():リストの作成(へ変換)tuple():タプルの作成(へ変換)
以下では別の基本的な関数を6つ紹介する。
sum()#
sum()は合計を計算する関数である。引数にリストやタプルを使う。
gdp_component = [10, 20, 30, 40]
sum(gdp_component)
100
abs()#
絶対値を返す。absはabsolute value(絶対値)の略。
abs(10.5)
10.5
abs(-10.5)
10.5
print()#
print()は表示するための関数であり,引数に表示したい値を置く。Jupyter Notebookではprint()を使わなくとも出力が表示される。例えば,
10
10
しかし複数行の場合は最後の行しか表示されない。
10
200
200
print()を使うと両方を表示することができる。
print(10)
print(200)
10
200
異なるオブジェクトを表示するには,を使う。
print('2020年の実質GDP:約', 500+25.7, '兆円')
2020年の実質GDP:約 525.7 兆円
文字列の中で\nは改行を示す。
print('マクロ\n経済学')
マクロ
経済学
次にf-stringを紹介する。文字列の前にfを書き加え,文字列の中で{}を使うことにより,割り当てた変数の値や計算結果などを表示することが可能となる。次の例を考えよう。
x = 2/3
print(f'3分の2は{x}です。')
3分の2は0.6666666666666666です。
四捨五入し小数点第3位まで表示する場合は,xの後に:.3fを付け加える。
print(f'3分の2は約{x:.3f}です。')
3分の2は約0.667です。
<:.3fの解釈>
:はこの後に続くコードは表示に関するものだと「宣言」している。.は小数点表示に関しての設定であることを示している。3は小数点第3位を示している。fはfloatのf
3fを5fにすると,小数点第5位までの四捨五入となる。試してみよう。
他の引数も指定することができる。次の2つを紹介する。
sep:複数の値を
,で区切って表示する際,値の間に入る区切り文字を指定する。デフォルトは半角スペース
end:行末にをどうするかを指定する
デフォルトは
\n(改行)
print('A','B','C')
print('A','B','C', sep='') # 区切り文字なし
print('A','B','C', sep='__')
A B C
ABC
A__B__C
print('A','B')
print('A','B', end='') # 改行なし
print('A', end='___')
A B
A BA___
range()#
range()は等差数列のオブジェクトを用意する関数である。次の書き方となる。
range(start,stop,step)
start:最初の整数(引数を与えない場合は0)stop:最後の整数の次の値step:隣接する整数の差(公差)(引数を与えない場合は1)
例えば,0から9までの10の整数を生成するには
range(10)
range(0, 10)
0から10までの整数が表示されないが,使えるように裏で準備されている。
次のコードは0から999,999,999(10億-1)までの10億個の整数を準備している。
range(1_000_000_000)
range(0, 1000000000)
一瞬にして10億個の整数が準備される「驚愕の速さ!」と言いたいが、実は、「準備」されただけで、10億個の整数が生成された訳ではない。実際に使うときに、0、1、2、3、、、と順番に整数の生成が実行されことになる。このように、各整数を使うときに「実行」することを遅延評価(lazy evaluation)と呼ぶ。「何のために使うの?」と思うだろう。理由は高速化のためであり、実際に10億個の整数からなるリストの作成には数十秒もしくは数分掛かる。例えば、次のシナリオを考えてみよう。10億個の正の整数のルートを計算するとし、計算プロセスが始まった後に計算する整数の数は(確率的に)決まるとする。10億個全ての整数を使うかもしれないが、もしかすると、7万個、もしくはたった5個の整数のルート計算だけで終わるかもしれない。その場合、10億個の整数を事前に作成する時間は無駄になるかも知れないし、あまりにも非効率的な手順だということは直ぐに理解できるのではないだろうか。順番に0、1、2、3、、、と必要な場合に整数の作成を実行する方が断然効率的だ。このように遅延評価するオブジェクトをジェネレーター(generator)と呼ぶ。range()関数は、後述するforループではよく使う関数なので覚えておこう!
list()#
リストを作成する関数。range(10)で準備した0から9までの整数をリストに格納しよう。
list(range(10))
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
list()関数を使って様々な例を表示しよう。
list(range(4,15+1))
[4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15]
list(range(4,30+1,2))
[4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26, 28, 30]
上の例ではstart\(<\)endとなっているが,不等号を逆にしてstepに負の整数を使うと降順の値が並ぶことになる。
list(range(10,0,-1))
[10, 9, 8, 7, 6, 5, 4, 3, 2, 1]
list(range(10,-10,-2))
[10, 8, 6, 4, 2, 0, -2, -4, -6, -8]
次のコードをアンコメントして(# を削除して)実行すると10億個の整数からなるリストを作成することができる。しかし、終了まで数分掛かるだろう!You are warned!
# list( range(1_000_000_000) )
len()#
要素の個数などを返す関数であり,引数としてリストやタプル,今後紹介する他のデータ型にも使える。
l = [0, 1, [2, 3, 4]]
t = (0, 1, (2, 3, 4))
d = {'a':0, 'b':1, 'c':2}
len(l), len(t), len(d)
(3, 3, 3)
dir()#
Pythonでは全てがオブジェクトと言われており,そのオブジェクトの「中身」を見るための関数がdir()(directoryの略)である。使い方は,以下でより詳しく説明する。
Note
ここで紹介した関数名は,type()関数のように英単語がそのまま使われる場合と,abs()関数のように英単語の省略形(absoluteの省略形)となっている場合がある。前者の場合はそのまま読めば良いが,後者の場合はどう発音すれば良いかと気になったりもする。決まった発音方法がある訳ではないので,好きに読めば良いのだが,次のパターンがあるようだ。
省略された単語の発音で読む。
str()を「ストリング関数」
アルファベットを一文字ずつ読む。
str()を「”s”,”t”,”r”関数」dir()を「”d”,”i”,”r”関数」
省略形を読むパターン。
len()は「レン関数」dir()は英単語”dirty”の”dir”と同じアルファベットなので,その発音に合わせて「ダー関数」次の章で説明する
elifはelse ifの省略形となるので「エリフ」と読む人が多いようだ。このサイトで説明はしないが特殊メソッドと呼ばれるものがあり,その一つに
.__repr__がある。これを「レパー」と読む人がいる。なぜこうなるかというと,repを「レップ」と読み,rは「アール」だが「ル」は殆ど発音しないので,2つを続けて読むと「レパー」となる。
help()#
組み込み関数help()を使うと関数やモジュールなど説明を表示させることができる。例えば,print()を例として挙げる。
help(print)
Help on built-in function print in module builtins:
print(*args, sep=' ', end='\n', file=None, flush=False)
Prints the values to a stream, or to sys.stdout by default.
sep
string inserted between values, default a space.
end
string appended after the last value, default a newline.
file
a file-like object (stream); defaults to the current sys.stdout.
flush
whether to forcibly flush the stream.
引数は関数名であり()は付いていないことに留意しよう。()を付けるとprint()を評価した結果に対しての説明が表示されることになる。英語での説明だがパターンを理解すればこれだけでも有用に感じることだろう。
help()の代わりに?を使うこともできる。
print?
?printも同じ結果を返す。
ユーザー定義の関数#
基本#
defを使って関数を定義し,引数が設定される(省略される場合もある)。ここでは基本となる引数のみを考えるが,引数の位置と=が重要な役割を果たすことになる。例を使いながら説明しよう。最初の例は数字の2乗を計算する関数である。
def func_0(x):
return x**2
1行目:
defで始まり(defはdefinitionの省略形):で終わる。func_0が関数名,xが第1引数(ひきすう)であり、この例では唯一の引数である。
2行目:
returnは評価した値を「戻す」もしくは「返す」という意味。必ずreturnの前にはインデント(通常4つの半角スペース)が必要であり,ないとエラーになる。x**2という戻り値(返り値)の設定をする
<returnについての補足>
実はreturnには2つの役割がある。一つは上述の様に,値を「戻す」もしくは「返す」という役割。そして,もう一つは関数の評価を終わらせること。今の段階では,二つ目の役割はそれほど重要ではないが,後述するループが関数の中で使われる場合,「関数を終了」させる役割が活躍することになる。例えば,この箇所のコードやこの箇所のコードを理解するためにはreturnの二つ目の役割を知っておくことが重要になる。
関数を評価するには,引数に数字を入れて実行する。
func_0(2)
4
引数が無い関数を定義することを可能である。
def func_100():
return 10**2
func_100()
100
print()関数を追加することもできる。
def func_kobe(x):
print('経済学はおもしろい(^o^)/')
return x**2
func_kobe(10)
経済学はおもしろい(^o^)/
100
引数の位置が重要#
引数が複数ある場合にその位置が重要になってくる。次の例を考えよう。
def func_1(a, b, c):
return a / b + c
func_1(10, 2, 10)
15.0
func_1(2, 10, 10)
10.2
実行する際に=を使う#
関数を実行する際、引数に=を使って値を指定することも可能である。この場合,引数の順番を変えることが可能となる。
func_1(10, c=10, b=2)
15.0
=が付いていない引数は該当する位置に書く必要があり,10が最初に来ないとエラーとなる。一般的なルールとして,=を使う引数は全て()の右端にまとめる。
関数を実行する際に
=無しで関数に渡される引数は,その位置が重要であるため位置引数と呼ばれる。関数を実行する際に
=付きで関数に渡される引数はキーワード引数と呼ばれる。
関数を定義する際に=を使う#
関数を定義する際に=を使って引数のデフォルトの値を設定することができる。即ち,引数を入力すると入力された数値を使うが,引数を入力しない場合は引数に予め設定した値(デフォルトの値)が使われて評価される。次の例ではcのデフォルトの値が10に設定されている。
def func_2(a, b, c=10):
return sum([a,b])*c
cの値を設定しない場合とする場合を比較してみる。
func_2(2, 3), func_2(2, 3, 100)
(50, 500)
Note
関数を定義する際の引数を「仮引数(parameter)」と呼ばれ,関数を実行する際の引数は「実引数(argument)」と呼ばれる。例としてfunc_2関数を考えると,a,b,cは仮引数である。関数を実行する次のコードでは,2,3,100が実引数となる。
func_2(2, 3, 100)
しかし一般的には両方とも単に「引数」と呼ぶことが多いだろう。
戻り値が複数の場合#
def func_3(x):
return x, x**2, x**3
func_3(3)
(3, 9, 27)
この場合、戻り値はタプルとして返される(タプルは,で定義されることを思い出そう)。次のコードは,変数dに戻り値を割り当てている。
d = func_3(3)
dを実行すると次の表示となる。
d
(3, 9, 27)
従って,次のようにそれぞれの要素にアクセスすることができる。
d0 = d[0]
d1 = d[1]
d2 = d[2]
print(d0)
print(d1)
print(d2)
3
9
27
一方,タプルのアンパッキングという方法を使うとd0,d1,d2への割り当てをより簡単におこなうことができる。アンパッキングを説明するために,次のコードを考えよう。
e0, e1, e2 = ('神戸', '大学', '経済')
print(e0)
print(e1)
print(e2)
神戸
大学
経済
このコードは次の割り当てを同時におこなっている。
神戸→e0大学→e1経済→e2
アンパッキングとは,「荷物をパッキングする」の反対の意味であり,上のコードは右辺の()で囲まれた要素を取り出して(アンパッキングして)左辺の変数に割り当てている。また,タプルはコンマ,で定義されるのを思い出そう。従って,右辺の()を省いて次のコードでも同じ結果となる。
e0, e1, e2 = '神戸', '大学', '経済'
これが複数の変数の同時割り当てで説明した=の「複数の変数の同時割り当て」である。
これを利用して,関数func_3の実行時に戻り値をd0,d1,d2に同時に割り当てることができる。
d0, d1, d2 = func_3(3)
print(d0)
print(d1)
print(d2)
3
9
27
Tip
上のコードの左辺もタプルなため,次のように書くこともできる。
(d0, d1, d2) = func_3(3)
しかしタプルは,で定義されるので、()を省いても問題ない。
ドキュメンテーション文字列#
文字列はシングルクォーテーション'もしくはダブルクォーテーション"を使い作成するが,それと別にドキュメンテーション文字列(docstring)というものがある。こちらも'もしくは"を使い,複数行にまたがって文字列を作成することができる。次の例は,the Zen of Python(Pythonコードを書く上での19の原則)と呼ばれる文章の一部である。
s = """Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts."""
print(s)
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
この例が示す様に,print関数を使うと改行も含めてそのまま表示される。
これを使ってユーザー定義の関数の説明を付け加えることにより,他人や将来の自分が関数を読む場合に可読性を高めることができる。次のような書き方となる。
def func_0(x):
"""この関数はxの2乗の値を返す。
引数:
x:整数型もしくは不動小数点型
戻り値:
xの2乗"""
return x**2
またhelp()関数を使うと付け加えて説明が表示されることになる。
help(func_0)
Help on function func_0 in module __main__:
func_0(x)
この関数はxの2乗の値を返す。
引数:
x:整数型もしくは不動小数点型
戻り値:
xの2乗
lambda関数#
defを使い複雑な関数を定義することができるが,単純な関数の場合,より簡単な方法がある。それがlambda関数である。例として,\(x^2\)を計算する関数を考えよう。
def function_name(x):
return x**2
この関数をlambda関数で書き直すと次の様になる。
function_name = lambda x: x**2
右辺にあるlambdaはlambda関数を定義する部分であり,defのように必ず必要である。実際に実行してみよう。
func_3 = lambda x: x**2
func_3(2)
4
経済学を考える#
将来価値#
t:時間(年; 0,1,2,…)i:名目利子率(例えば,0.02)r:実質利子率(例えば,0.05)pi:インフレ率(例えば,0.03)
次の式が成立する。
x万円を年率i%の利息を得る金融商品に投資し,t年後に現金化するとしよう。その間のインフレ率はpi%とした場合のx万円の実質将来価値を計算する関数を考える。
def future_value(x, i, pi, t):
r = (1+i)/(1+pi)-1
return x*(1+r)**t
future_value(100, 0.05, 0.03, 10)
121.20505797930663
現在価値#
t年後にx万円をもらえるとしよう。x万円の現在価値を計算する関数を考える。
def current_value(x, i, inf, t):
r = (1+i)/(1+inf)-1
return x/(1+r)**t
current_value(100, 0.05, 0.03, 10)
82.50480769298673
複利計算#
y0:元金t:投資期間r:実質利子率(年率)m:複利の周期(年間の利息発生回数)例えば,毎月利息が発生する場合は
m=12
yt:t年後の元利合計
t年後の元利合計を計算する関数を考えよう。
def calculate_yt(y0=100, r=0.05, m=1, t=10):
return y0*( 1+r/m )**(m*t)
calculate_yt()
162.8894626777442
calculate_yt(m=12)
164.700949769028
オブジェクトと属性#
属性について#
Pythonを習うと「オブジェクト」という単語が必ず出てくる。今の内にイメージをつかむために自転車をオブジェクトの例として考えてみよう。通常の自転車には車輪が2つあり、サドルが1つあり、左右にペダルが2つある。これらの数字が自転車に関するデータである。またペダルを踏むことにより前に動き、ハンドルを右にきると右方向に進むことになる。即ち、あることを実行すると、ある結果が返されるのである。これは数学の関数と同じように理解できる。\(y=x^2\)の場合、\(x\)が2であれば\(y\)の値として4が返される。このように自転車はデータと関数が備わっているオブジェクトとして考えることができる。また、車輪の数やペダルを踏むことは自転車特有のデータと関数であり、他のオブジェクト(例えば、冷蔵庫)にはない。即ち、世の中の「オブジェクト」にはそれぞれ異なるデータと関数が存在していると考えることができる。
Pythonの世界でもすべてをこれと同じように考える。コードセルに書いた10を実行すると,その10がオブジェクトであり,データと関数が備わることになる。それらを属性(attributes)と呼ぶ。10は単なる数字に見えるが、実は様々な属性から構成されるオブジェクトなのである。上の例の自転車のように、属性は次の2つに分類される。10を例にとると、
10が持つ様々なデータ属性(data attribute)(例えば、10という値や整数という情報)10特有の関数であるメソッド(method)(例えば、加算、除算のように10というデータに働きかける関数)
を指す(呼称についてはPythonの公式サイトを参照)。自転車と冷蔵庫は異なるデータと関数を持つように、整数10と文字列マクロ経済学は異なるデータと関数を備えるオブジェクトなのである。この考え方はPythonのすべてに当てはまる。即ち、Everything is an object in Python.
Note
データ属性もメソッドもオブジェクトの属性には変わりないが,これ以降このサイトではこの2つを次のように呼ぶことにする。
データ属性 → 「属性」
メソッド → 「メソッド」
属性の例を考えるために浮動小数点型10.0をyに割り当てよう。
y = 10.0
yの属性はdir()という組み込み関数を使うことにより表示できる。
dir(y)
['__abs__',
'__add__',
'__bool__',
'__ceil__',
'__class__',
'__delattr__',
'__dir__',
'__divmod__',
'__doc__',
'__eq__',
'__float__',
'__floor__',
'__floordiv__',
'__format__',
'__ge__',
'__getattribute__',
'__getformat__',
'__getnewargs__',
'__getstate__',
'__gt__',
'__hash__',
'__init__',
'__init_subclass__',
'__int__',
'__le__',
'__lt__',
'__mod__',
'__mul__',
'__ne__',
'__neg__',
'__new__',
'__pos__',
'__pow__',
'__radd__',
'__rdivmod__',
'__reduce__',
'__reduce_ex__',
'__repr__',
'__rfloordiv__',
'__rmod__',
'__rmul__',
'__round__',
'__rpow__',
'__rsub__',
'__rtruediv__',
'__setattr__',
'__sizeof__',
'__str__',
'__sub__',
'__subclasshook__',
'__truediv__',
'__trunc__',
'as_integer_ratio',
'conjugate',
'fromhex',
'hex',
'imag',
'is_integer',
'real']
この中の最後にあるrealは数字の実部を表し,実数である10.0の実部は10.0である。一方,imagは複素数の虚部を表すが,10.0は複素数ではないので0.0になっている。(上で紹介しなかったが,データ型に複素数型もある。)
y.real, y.imag
(10.0, 0.0)
上の属性のリストにある_はアンダースコア(underscore)と呼ぶが,2つ連続した場合__となりダブル・アンダースコア(double underscore)と呼ぶ。長いのでダンダー(dunder)と省略する場合が多々ある。また,.__init__のような属性は特殊属性と呼ばれるが,ダンダー属性と呼ぶこともある。ダンダー属性はPythonが裏で使うものでありユーザーが直接使う属性ではない。
次にメソッドを考えるために次のリストを例に挙げる。
my_list = [1,2,3]
dir(my_list)
['__add__',
'__class__',
'__class_getitem__',
'__contains__',
'__delattr__',
'__delitem__',
'__dir__',
'__doc__',
'__eq__',
'__format__',
'__ge__',
'__getattribute__',
'__getitem__',
'__getstate__',
'__gt__',
'__hash__',
'__iadd__',
'__imul__',
'__init__',
'__init_subclass__',
'__iter__',
'__le__',
'__len__',
'__lt__',
'__mul__',
'__ne__',
'__new__',
'__reduce__',
'__reduce_ex__',
'__repr__',
'__reversed__',
'__rmul__',
'__setattr__',
'__setitem__',
'__sizeof__',
'__str__',
'__subclasshook__',
'append',
'clear',
'copy',
'count',
'extend',
'index',
'insert',
'pop',
'remove',
'reverse',
'sort']
この中にappendがあるが,my_listに要素を追加するメソッドであることは説明した。
my_list.append(100)
my_list
[1, 2, 3, 100]
Note
(データ)属性と異なりメソッドは
()が必要となる。これは関数の()に対応している。()を「する」もしくは「実行する」と読めば分かりやすいだろう。
関数とメソッドの違い#
本章の最初で関数について説明し,ここではメソッドについて解説した。その説明を読んでも,関数とメソッドの違いが不明瞭だと感じる読者もいるだろう。ここでは,その違いを再度考えてみる。関数とメソッドの役割は基本的には同じだが,で異なる点を図Fig. 1にまとめた。
まず,コードを実行するとメモリー上にデータが保存され,それをオブジェクトと呼ぶことはもう分かっているだろう。例えば,x=[1,2,3]を実行すると,メモリー上に[1,2,3]が保存され,その参照記号がxとなる。この場合,[1,2,3]がオブジェクトである。同様に,y=10を実行すると,10というオブジェクトが保存される(yは参照記号)。
関数の特徴は,様々なオブジェクトに適用できることだ。print()関数は,異なるオブジェクトであるxにもyにも使うことができる。そういう意味では,関数を適用できる用途は広い。図Fig. 1にあるように,イメージ的には,様々な用途に使える懐中電灯のようなものだろうか。
一方,メソッドはオブジェクトに元々備わっている関数である。例えば,.append()はリストである[1,2,3]に備わっている関数であり,整数型である10には備わっていない。.append()は,それが実装されている[1,2,3]に働きかける関数であり,実行後にその結果を返すことになる。そういう意味では,メソッドの用途は限られている。図Fig. 1にあるように,車のヘッドライトをイメージしてはどうだろうか。ヘッドライトは,夜走行する際に,安全のために装備された車の前方を照らすことが主な目的であり,他の用途に使うことは不可能ではないだろうが,難しいのではないだろうか。もう一点付け加えると,x.append(100)の場合,100をxに追加するが,その裏では()の中にxが引数として設定されことになる。
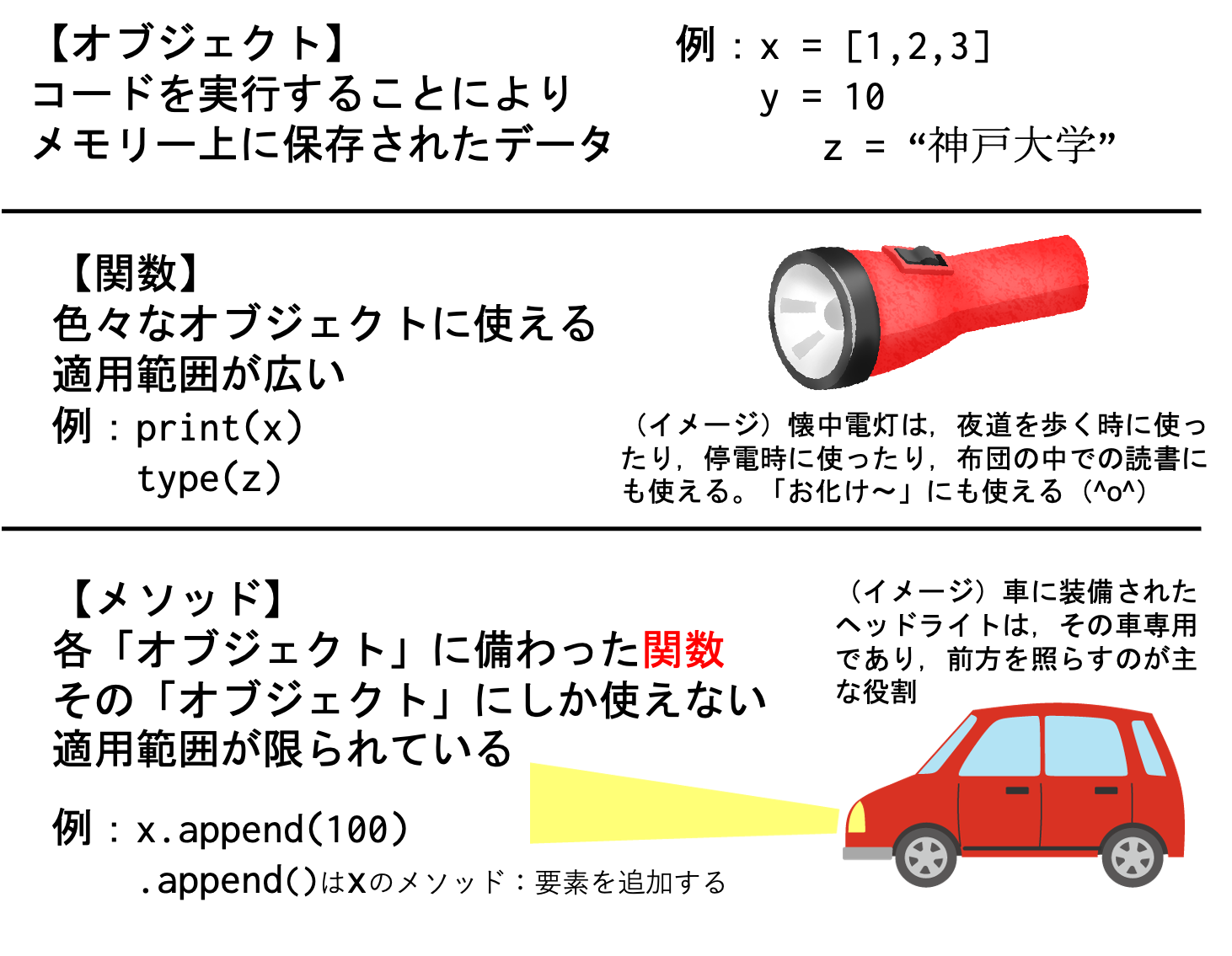
Fig. 1 関数とメソッドの違い#
スコープ#
値を表示する関数
x = 100 / 3
print(x)
33.333333333333336
説明#
スコープとは、変数が所属し直接アクセスできるコードの中の「領域」を示す。類似する概念に名前空間(Namespace)もあるが、スコープの情報を記す「表」のことであり、スコープ(Scope)と同義と理解すれば良い。
ここでは基本的に以下のように理解すれば良いであろう。
Jupyter Notebookを開始した時点からglobalスコープが始まる。
関数を定義すると、その関数の範囲内でlocalスコープが生成される。
globalスコープで定義された変数は、localスコープからアクセスできるが、globalスコープからlocalスコープの変数にはアクセスできない。
関数を実行すると次の順番で変数を探す。
関数のローカス・スコープ
グローバル・スコープ
次の例を考えよう。
s = "Kobe Univ" # globalスコープ
def scope_0():
s = "神戸大学" # localスコープ
return s
scope_0()
'神戸大学'
この関数を実行すると、Pythonはまず関数scope_0のローカル・スコープ内で変数sを探すことになる。ローカル・スコープにsがあるので、それを返している。次の関数を考えよう。
def scope_1():
return s
scope_1()
'Kobe Univ'
この例では、まずPythonはローカル・スコープにsがあるかを確かめる。ローカル・スコープにないため、次にグローバル・スコープにsがないかを確かめている。グローバル・スコープにsがあったので、それを返している(ないとエラーが出る)。
次の例では、グローバル・スコープからローカル・スコープの変数へのアクセスを考える。
def scope_2():
s_local = 'Pythonは楽しい(^o^)/'
return s_local
scope_2()
'Pythonは楽しい(^o^)/'
s_localは関数scope_2のローカル・スコープで定義されている。グローバル・スコープからアクセスしようとするとエラーが発生する。
s_local
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[64], line 1
----> 1 s_local
NameError: name 's_local' is not defined
以上の説明を図Fig. 2にまとめる次のようになる。
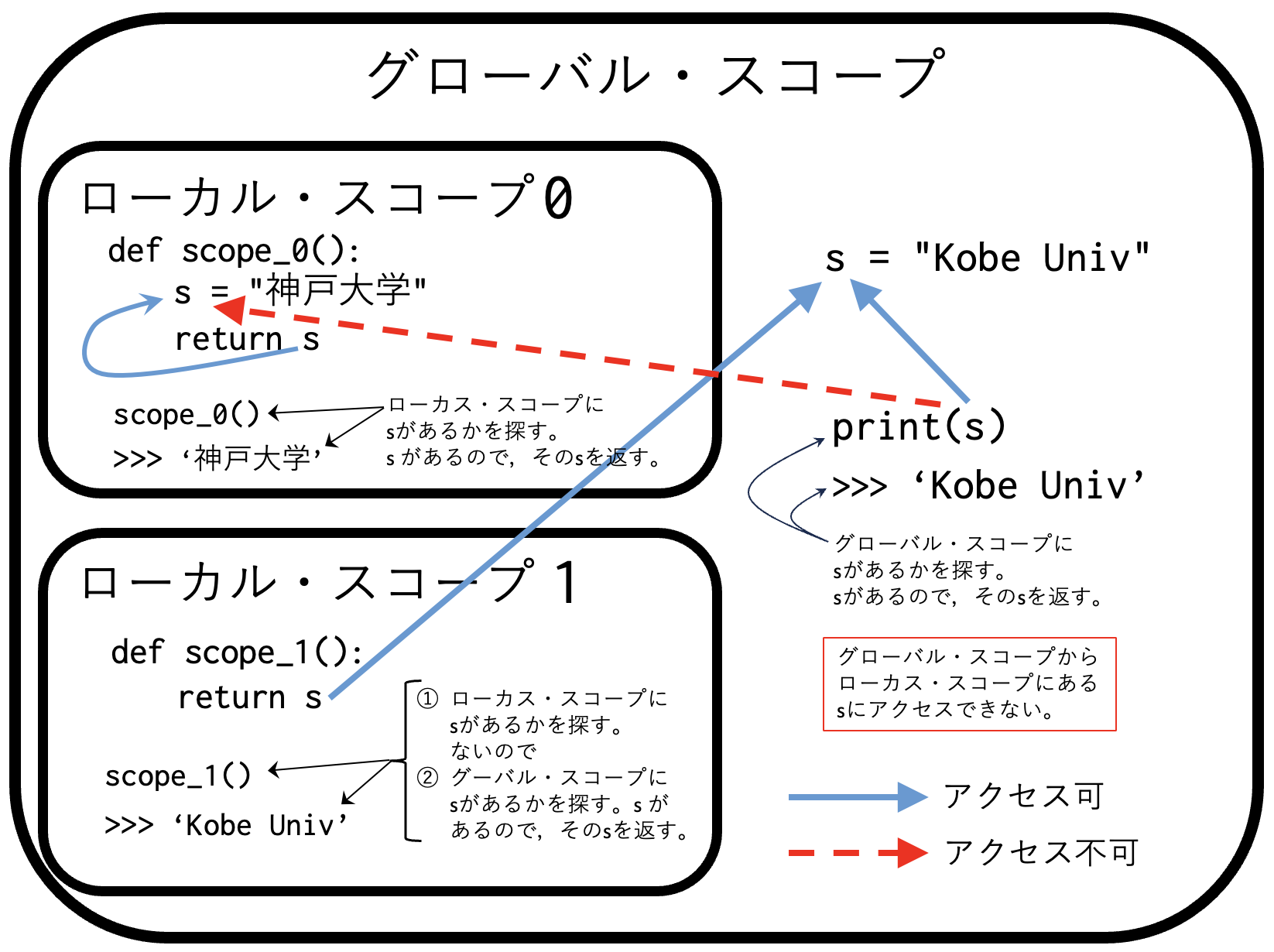
Fig. 2 グローバル・スコープとローカル・スコープの関係#
教訓1#
関数内で使う変数は、可能な限り関数内で定義する方が意図しない結果につながるリスクを軽減できる。
グローバル・スコープで定義した変数を関数に使いたい場合は、引数として同じ変数を使う。
次の例を考えよう。
a = 4
ここでaに4を割り当てたが,この値を忘れて(知らずに)10だったと勘違いして次の関数を定義したとしよう。
def scope_3(x):
return x + a
scope_3(10)は20を返すと思って実行すると意図しない結果になる。
scope_3(10)
14
このような場合はaを引数に使うことにより問題を回避できる。aは10として関数を実行すると意図した結果となる。
def scope_4(x,a):
return x + a
scope_4(10,10)
20
この場合、関数scope_4(x,a)のaはローカル・スコープで定義され、グルーバル・スコープのaとは異なる。実際、グルーバル・スコープのaの値を確認してみると以前と同じ値4である。
a
4
ちなみに、グローバル・スコープの変数名や関数名は%whoもしくは%whosのコマンドで確認できる。
%who
a calculate_yt current_value d d0 d1 d2 e0 e1
e2 func_0 func_1 func_100 func_2 func_3 func_kobe future_value gdp_component
l my_list s scope_0 scope_1 scope_2 scope_3 scope_4 t
warnings x y
このリストにあるsはグローバル・スコープのsである。またローカル・スコープにあるs_localはこのリストには含まれていない。
教訓2#
forループの1行目に使う変数は再割り当てされても構わない変数を使おう。
forループは次の章で出てくるので,この箇所はスキップして良いだろう。だが,forループを学んだ後,もう一度こちらに戻ってきて読んでみよう。
例を使って説明しよう。
for i in range(5):
print(i)
0
1
2
3
4
このforループのiはrange(5)の連番0、1、2、3、4を指す変数として使われるが、グローバル・スコープの変数として存在し、ループの最後の値が割り当てられている。確認してみよう。
i
4
forループで使う変数は、ループ用の変数を使うようにしよう。