Matplotlib:図示#
説明#
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 警告メッセージを非表示
import warnings
warnings.filterwarnings("ignore")
Matplotlib is building the font cache; this may take a moment.
Matplotlib(「マットプロットリブ」と読む)はプロットのための代表的なパッケージであり、ここではその使い方を解説する。プロットにはMatplotlibのモジュールであるpyplotを使うことになる。慣例に沿ってpltとしてインポートする。
pyplotモジュールを使ってプロットする場合、主に3つのコードの書き方がる。
書き方1:(オブジェクト指向)
fig = plt.figure()
ax = fig.add_subplot()
ax.plot(...)
書き方2:(オブジェクト指向)
fig, ax = plt.subplots()
ax.plot(...)
書き方3: Matlabという有料ソフトのコードに沿った書き方
plt.plot(...)
本サイトでは書き方2に沿ってMatplotlibの使い方を説明する。一方で,その裏にある考え方を理解するには、書き方1から始めた方が良いと思うので,書き方1の簡単な説明をすることにする。Fig. 1は,Matplotlibが描画する図の階層的な構造を示している。ここで重要なのは「キャンバス」と「軸」の違いである。
Matplotlibによるプロットは次の図のような構成となっている。
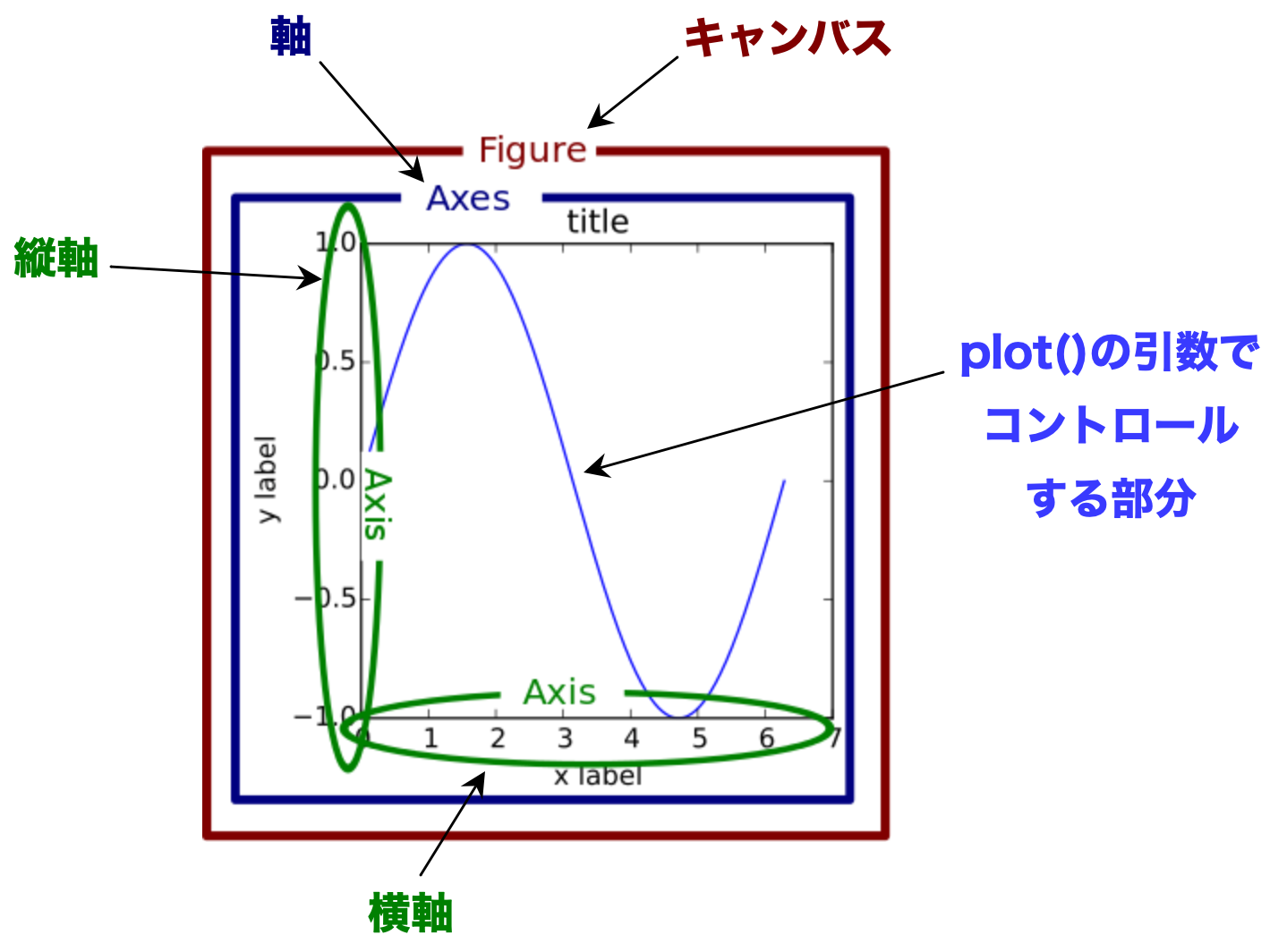
Fig. 1 キャンバスと軸の関係#
キャンバスとは表示される領域であり,実際には表示されない透明のキャンバ」である。
書き方1と書き方2では変数
figがキャンバスを表している。figureやfigなどの変数名や引数名があれば、キャンバスを指していると理解すれば良いだろう。
軸とは1つの図を表示する区域である。
書き方1と書き方2では変数
axが軸を表している。axやaxesなどの変数名や引数名があれば、軸を表していると理解すれば良いだろう。キャンバス上に複数のグラフを表示する場合は複数の区域を設定する必要がある。
これを踏まえて,書き方1は次のような手順で描画していと解釈できる。
キャンバスを用意する。
それを行なっているのが1行目である。右辺の
plt.figure()でキャンバスを作成し、それを変数figに割り当てている。
キャンバスに軸を追加する。
これをおこなっているのが2行目である。右辺では、キャンバス
figのメソッドadd_subplot()を使いキャンバスに軸を追加し、それを左辺の変数axに割り当てている。実際に、書き方1の2行のコードを実行すると透明のキャンバス上に軸が表示される。(試してみよう。)作成された軸
axにメソッドplot()などを使い直線・曲線・点など付け加えたり、タイトルなどの「飾り付け」をおこない作図することになる。1つのキャンバスに複数の軸を作成し,複数の図を表示することが可能となる。
この説明でわかることは、Matplotlibで表示される図は透明のキャンバス上に描かれ装飾された軸ということである。以下の説明では、「図」はキャンバス全体に表示されたものを指す場合もあれば,ある一つの軸に表示されたものを指す場合もああるので,文脈で判断してほしい。
さて書き方2に話を戻すと、既に察している読者もいるかも知れないが、1行目は書き方1の最初の2行を1行に省略したものである。右辺のplt.subplots()は透明のキャンバスと軸の2つをタプルとして返す。最初の要素がキャンバスでありそれを左辺のfigに、2つ目の要素が軸でありaxに割り当てている。実際、1行目だけを実行すると軸が表示される。後は書き方1同様、axのメソッドplot()などを使い軸を飾り付けして作図することになる。
ちなみに、書き方3は書き方2の3行を1行に省略した形と解釈して良いだろう。本来はMatlab(有料)ユーザーのPythonへの移行を促す為に用意された書き方である。
次にplot()のデータに関する引数について説明するが,主に2つの設定方法がある。
データの引数の書き方1:
plot(<横軸のデータ>, <縦軸のデータ>)
データの引数の書き方2:変数のラベル名が使える場合(PandasのDataFrame)
plot(<横軸の変数名>, <縦軸の変数名>, data=<データ名>)
この2つの書き方の簡略形として,横軸の変数を省略することもできる。
plot(<縦軸のデータ>)
plot(<縦軸の変数名>, data=<データ名>)
この場合,横軸には縦軸のデータのインデックス番号が使われることになる。手っ取り早く図示したい場合は良いかも知れない。
以下ではそれぞれの引数の書き方について解説する。
データの引数の書き方1#
arrayを使って#
プロットするデータを生成しよう。変数xに横軸に使うデータを次のように割り当てる。
x = np.linspace(-2, 2, 3)
x
array([-2., 0., 2.])
3つの要素からなるarrayである。縦軸のデータとしてy0を用意する。
y0 = x**2
y0
array([4., 0., 4.])
同じようにy0も3つの要素からなるarrayである。プロットしてみよう。
fig, ax = plt.subplots()
ax.plot(x, y0, marker='o')
[<matplotlib.lines.Line2D at 0x113f1b050>]
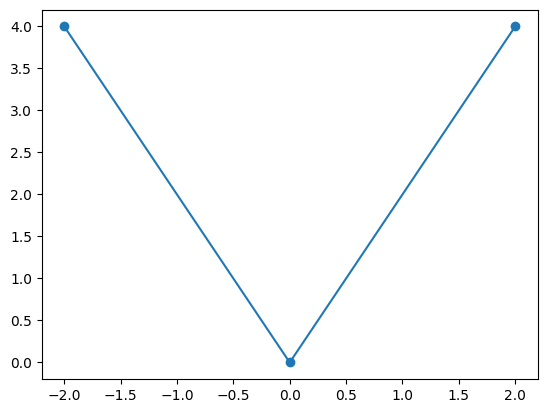
2行目にmarker='o'が追加されているが,「●」を表示するために使っている。このような引数の使い方は後で詳しく説明するので,ここでは気にしないで読み進めて欲しい。
「●」のマーカーがある点がxとy0のarray要素の組み合わせとして表示されている。plot()はデフォルトでそれらの点を直線で結んでいる。この場合,データの組み合わせが3点しかないため\(y=x^2\)の形を明確に表示できていない。言い換えると,データの組み合わせの数を増やすことにより\(y=x^2\)をより正確に表示されることになる。もう一度,xとy0のデータを生成しなおす。
x = np.linspace(-2, 2, 100)
y0 = x**2
xとy0にはそれぞれ100の要素があり,これらを使うことにより100のデータの組み合わせが成立することになる。プロットしてみよう。
fig, ax = plt.subplots()
ax.plot(x, y0, marker='o')
[<matplotlib.lines.Line2D at 0x1140e4bf0>]
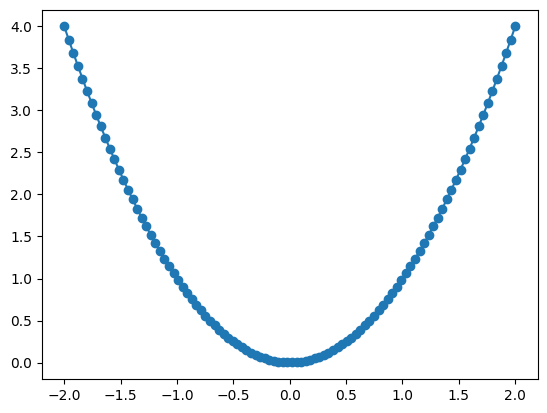
より\(y=x^2\)の図に近づいたことがわかる。
(注意点)
上の2つの図の上に文字が表示されているが,表示したくない場合は最後に
;を加えるか次の行にpassと書くと表示されなくなる。xを省いてax.plot(y0)としても同じような図が表示されるが,横軸の値がデータの数に対応することになり,意図した図と異なることになる。
次に縦軸のデータとして,2つを用意する。
y1 = x+1
y2 = np.exp(x)
y0,y1,y2を同じ軸にプロットしてみよう。コードは簡単でax.plot()をリピートするだけである。
fig, ax = plt.subplots()
ax.plot(x, y0)
ax.plot(x, y1)
ax.plot(x, y2)
pass
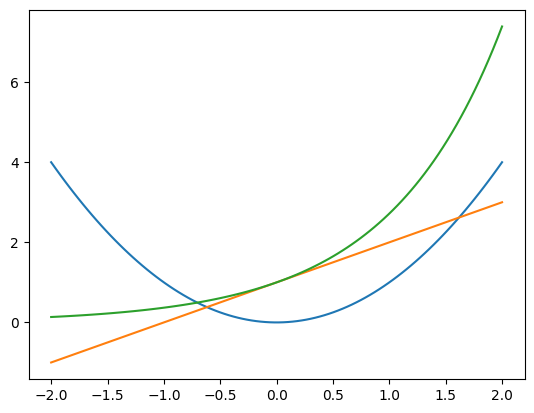
それぞれのax.plot()を「軸axにデータの組み合わせをプロットする」と読めば理解しやすいと思う。また同じようなコードが続いているので,次のようにforループを使うことより短いコードで同じ図を表示することができる。
fig, ax = plt.subplots()
for y in [y0, y1, y2]:
ax.plot(x, y)
pass
DataFrameを使って#
まずDataFrameを作成しよう。
dic = {'X':x, 'Y0':y0, 'Y1':y1, 'Y2':y2} # 辞書の作成
df0 = pd.DataFrame(dic) # DataFrameの作成
df0.head()
| X | Y0 | Y1 | Y2 | |
|---|---|---|---|---|
| 0 | -2.000000 | 4.000000 | -1.000000 | 0.135335 |
| 1 | -1.959596 | 3.840016 | -0.959596 | 0.140915 |
| 2 | -1.919192 | 3.683298 | -0.919192 | 0.146725 |
| 3 | -1.878788 | 3.529844 | -0.878788 | 0.152775 |
| 4 | -1.838384 | 3.379655 | -0.838384 | 0.159074 |
横軸にX,縦軸にY0をプロットしてみる。
fig, ax = plt.subplots()
ax.plot(df0['X'],df0['Y0'])
pass
横軸にX,縦軸にY0,Y1,Y2をプロットしてみる。
fig, ax = plt.subplots()
ax.plot(df0['X'],df0['Y0'])
ax.plot(df0['X'],df0['Y1'])
ax.plot(df0['X'],df0['Y2'])
pass
引数の書き方1の簡略形として,横軸の変数を省略できることを紹介した。その場合はどうなるかを考えてみよう。
fig, ax = plt.subplots()
ax.plot(df0['Y0'])
pass
上の図との違いは横軸の値である。この場合,横軸にdf0の行インデックスが自動的に使われている。
データの引数の書き方2#
次に引数dataを使う書き方を考えてみる。
同じDataFrameを使う#
横軸にX,縦軸にY0を指定してプロットしてみる。
fig, ax = plt.subplots()
ax.plot('X', 'Y0', data=df0)
pass
変数Y1とY2も同じ軸axにプロットしてみよう。
fig, ax = plt.subplots()
ax.plot('X', 'Y0', data=df0)
ax.plot('X', 'Y1', data=df0)
ax.plot('X', 'Y2', data=df0)
pass
Note
この場合,同じようなコードが続いているのでforループを使うと良いだろう。
fig, ax = plt.subplots()
for v in ['Y0','Y1','Y2']:
ax.plot('X', v, data=df0)
横軸のXを指定せずにプロットしてみよう。
fig, ax = plt.subplots()
ax.plot('Y0', data=df0)
pass
行インデックスが横軸の値として使われている。
異なるDataFrameの変数を図示する#
別のDataFrameを作成する。
dic = {'X':x, 'Y3':-x-1, 'Y4':-x**2}
df1 = pd.DataFrame(dic)
df1.head()
| X | Y3 | Y4 | |
|---|---|---|---|
| 0 | -2.000000 | 1.000000 | -4.000000 |
| 1 | -1.959596 | 0.959596 | -3.840016 |
| 2 | -1.919192 | 0.919192 | -3.683298 |
| 3 | -1.878788 | 0.878788 | -3.529844 |
| 4 | -1.838384 | 0.838384 | -3.379655 |
Xを横軸としてdf0のY0,Y3を横軸としてdf1のY3を同じ図に表示してみよう。
fig, ax = plt.subplots()
ax.plot('X', 'Y0', data=df0)
ax.plot('Y3', 'Y4', data=df1)
pass
その他の引数とメソッド#
上で説明したコードでは単純なプロットしかできない。一方で様々な引数やメソッドが用意されており,それらを駆使することにより様々な「飾り付け」をすることが可能となる。ここでは主なものを紹介するが,他にも数多く用意されているのでMatplotlibのサイトを参考にしてほしい。また,これらの引数・メソッドは,上述の「データの引数の書き方1」と「データの引数の書き方2」の両方に有効であることも覚えておこう。
引数・メソッドがもたらす違いを際立たせるために新たなDataFrameを使おう。
dic = {'X':[10, 20, 30],
'Y':[5.0, 30.0, 15.0],
'Z':[7.0, 2.0, 10.0]}
df2 = pd.DataFrame(dic)
df2.head()
| X | Y | Z | |
|---|---|---|---|
| 0 | 10 | 5.0 | 7.0 |
| 1 | 20 | 30.0 | 2.0 |
| 2 | 30 | 15.0 | 10.0 |
以下のプロットでは,横軸の変数を省略する簡略形を使うので,行インデックが横軸に使われるので注意しよう。
subplots()の引数#
subplots()はキャンバスと軸を設定するpltのメソッドとなるが、主に3つの引数を紹介する。
figsize:図の大きさfigsize=(キャンバスの横幅、キャンバスの縦の長さ)
nrows(デフォルトは1):軸の数を指定するために使う引数(「図を並べる」のセクションで説明する)ncols(デフォルトは1):軸の数を指定するために使う引数(「図を並べる」のセクションで説明する)sharex(デフォルトはFalse):複数の軸がある場合に使う引数(「図を並べる」のセクションで説明する)sharey(デフォルトはFalse):複数の軸がある場合に使う引数(「図を並べる」のセクションで説明する)constrained_layout(デフォルトはFalse):複数の軸がある場合に使う引数であり,図の間隔を自動調整する(「図を並べる」のセクションで説明する)
fix, ax = plt.subplots(figsize=(8,4))
ax.plot('X', data=df2)
pass
plot()の基本的な引数#
plot()は軸axにデータを描くメソッドだが、引数を使うことによりデータの表示方法を指定できる。詳しくはこのリンクを参照することにして,ここでは基本的な引数だけを紹介する。
linestyle:線のスタイル(リストにして列の順番で指定する;-,--,-.,:などがある)linewidthorlw:線の幅colororc:色(参照サイト)rは赤kは黒gはグリーン
marker:観測値のマーカー(o,.,>,^などがある; 参照サイト)markersize:マーカーの大きさlabel:以下で説明するax.legend()がある場合に有効となる
fix, ax = plt.subplots()
ax.plot('X'
, data=df2
, linestyle=':'
, linewidth=2
, color='red'
, marker='o'
, markersize=10
, label='X series')
ax.plot('Y'
, data=df2
, linestyle='-'
, linewidth=2
, color='k'
, marker='^'
, markersize=10
, label='X series')
pass
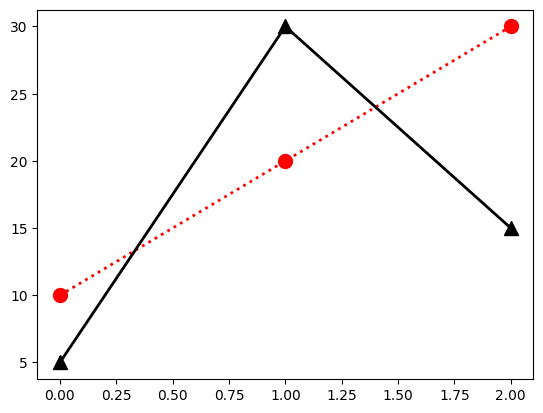
引数をいちいち書くのが面倒な場合、次の3つを簡略して一緒に指定できる。
linestylecolormarker
例えば、
linestyle=':'color='red'marker='o'
の場合、:roと書くことができる。
fix, ax = plt.subplots()
ax.plot('Y', ':ro', data=df2)
pass
(注意点)
:roは文字列:,r,oの順番を変えても良い。:や:oのように1つもしくは2つだけを指定しても良い。:roは=を使う引数の前に置く。
詳細は参考サイト(英語)を参照。
axの基本的なメソッド#
axは透明なキャンバス上にある軸を指しているが、そのメソッドを使うことにより、軸周辺を「飾り付け」することができる。
.set_title():タイトルを設定する。文字列で指定し、大きさは引数
sizeで指定する。
.set_xlabel():横軸ラベル文字列で指定し、大きさは引数
sizeで指定する。
.set_ylabel():縦軸ラベル文字列で指定し、大きさは引数
sizeで指定する。
.legend():凡例を表示する。plot()の引数labelがなければ、データ・フレームの列ラベルが使われる。plot()の引数labelがあれば、それが使われる。
.grid():グリッド線が表示される。
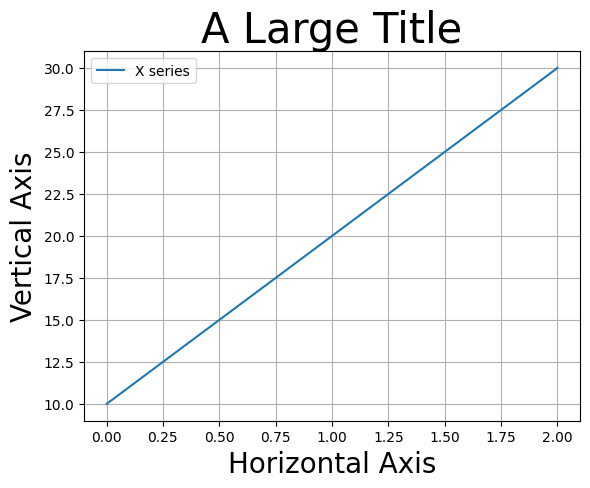
fig, ax = plt.subplots()
ax.plot('X', data=df2, label='X series')
ax.set_title('A Large Title', size= 30) # タイトルの設定
ax.set_xlabel('Horizontal Axis', size=20) # 横軸ラベルの設定
ax.set_ylabel('Vertical Axis', size=20) # 縦軸ラベルの設定
ax.legend()
ax.grid()
pass
図を並べる#
複数の図を並べたいとしよう。考え方としては、透明のキャンバスに複数の軸を設定し、それぞれの軸を使って作図していけば良いのである。キャンバスは四角なので偶数個の軸が設定できる。例として、次のように軸を配置したいとしよう。
+---+---+---+
| 1 | 2 | 3 |
+---+---+---+
| 4 | 5 | 6 |
+---+---+---+
2行・3列の配置になっており、左上から軸の番号が振られている。このような場合、subplots()の2つの引数が必須であり、別の2つの引数が有用である。
subplots(行の数, 列の数, sharex=False, sharey=False, constrained_layout=False)
行の数(デフォルトは
1):上の例では2列の数(デフォルトは
1):上の例では3sharex(デフォルトはFalse):Trueにすると、全ての図で横軸が同じになり、不要な横軸の数字などを非表示になる。sharey(デフォルトはFalse):Tureにすると、全ての図で縦軸が同じになり、不要な縦軸の数字などを非表示にするconstrained_layout(デフォルトはFalse):Tureにすると、全ての図の間隔を調整して見やすくなる。
上の例を使うと次のようになる。
fig, ax = plt.subplots(2,3)
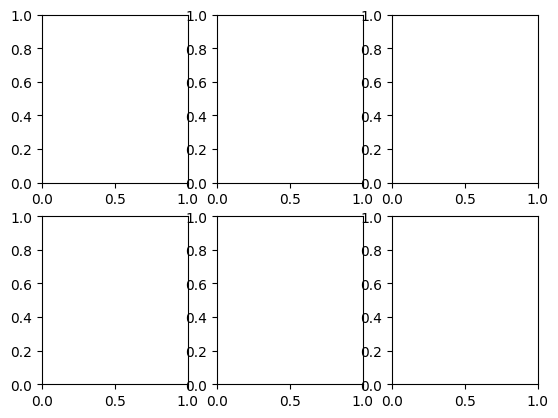
6つの軸が表示されているが、それらはaxに割り当てられている。axを表示してみよう。
ax
array([[<Axes: >, <Axes: >, <Axes: >],
[<Axes: >, <Axes: >, <Axes: >]], dtype=object)
<AxesSubplot:>が軸を示しており、それぞれの軸に対応している。
ax.shape
(2, 3)
軸は(2,3)のarrayに格納されているのが確認できる。従って、それぞれの軸はarrayの要素を抽出することによりアクセスできる。
ax[0,0]:軸1を抽出ax[0,1]:軸2を抽出ax[0,2]:軸3を抽出ax[1,0]:軸4を抽出ax[1,1]:軸5を抽出ax[1,2]:軸6を抽出
これを使い次のように6つのを図示できる。
fig, ax = plt.subplots(2,3,figsize=(8,3))
ax[0,0].plot('X', data=df2)
ax[0,1].plot('Y', data=df2)
ax[0,2].plot('Z', data=df2)
ax[1,0].plot('X', data=df2)
ax[1,1].plot('Y', data=df2)
ax[1,2].plot('Z', data=df2)
pass
横軸と縦軸を共有するには次のようにする。
fig, ax = plt.subplots(2,3,figsize=(8,3),sharex=True,sharey=True)
ax[0,0].plot('X', data=df2)
ax[0,1].plot('Y', data=df2)
ax[0,2].plot('Z', data=df2)
ax[1,0].plot('X', data=df2)
ax[1,1].plot('Y', data=df2)
ax[1,2].plot('Z', data=df2)
pass
axのメソッド(例えば、軸のタイトル)はそれぞれ設定することができる。
次に、キャンバス全体のタイトルを設定したいとしよう。キャンバスはfigに割り当てられているので、そのメソッドsuptitleを使い表示することができる。
fig, ax = plt.subplots(2, 3, figsize=(8,3),
sharex=True, sharey=True,
constrained_layout=True)
ax[0,0].plot('X', data=df2)
ax[0,0].set_title('ax[0,0]')
ax[0,1].plot('Y', data=df2)
ax[0,1].set_title('ax[0,1]')
ax[0,2].plot('Z', data=df2)
ax[0,2].set_title('ax[0,2]')
ax[1,0].plot('X', data=df2)
ax[1,0].set_title('ax[1,0]')
ax[1,1].plot('Y', data=df2)
ax[1,1].set_title('ax[1,1]')
ax[1,2].plot('Z', data=df2)
ax[1,2].set_title('ax[1,2]')
fig.suptitle("Grand Title", fontsize=20)
pass
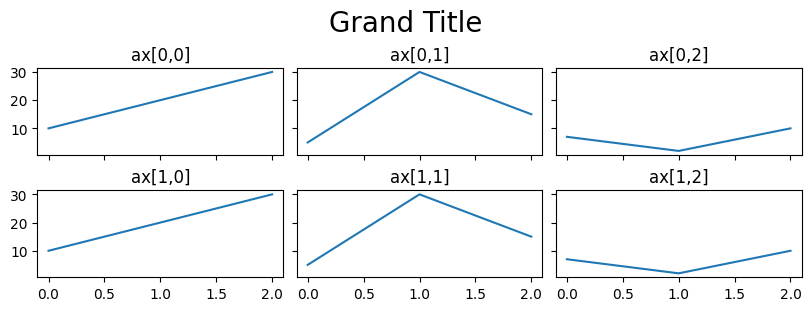
2軸グラフ#
複数のデータを表示する際、右の縦軸を使いデータを表示したい場合がある。例を使って説明することにする。
fig, ax1 = plt.subplots() # (1)
ax2 = ax1.twinx() # (2)
ax1.plot('X', data=df2) # (3)
ax2.plot('Z', data=df2) # (4)
pass
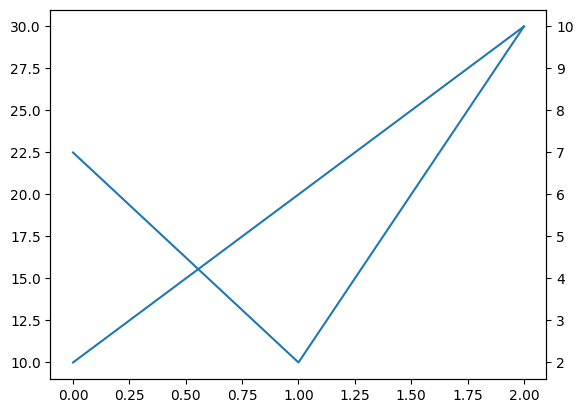
コードの説明
キャンバスと軸を作成し、軸を
ax1に割り当てる。
ax1のメソッドtwinx()を使い、右の縦軸を準備しax2に割り当てる。
ax1にXをプロットする。
ax2にZをプロットする。
また上で説明した方法で様々な「飾り付け」をすることができる。ただ、凡例については少し追加的なコードが必要となるので、それについても簡単に以下で説明する。
fig, ax1 = plt.subplots()
ax2 = ax1.twinx()
ax1.plot('X', 'k-o', data=df2, label='X series')
ax2.plot('Z', 'r:', data=df2, label='Z series')
ax1.set_title('Title', size=20) # (1)
ax1.set_ylabel('X data', size=15) # (2)
ax2.set_ylabel('Z data', size=15) # (3)
ax1.legend() # (4)
ax2.legend(loc=(0.015,0.81)) # (5)
pass
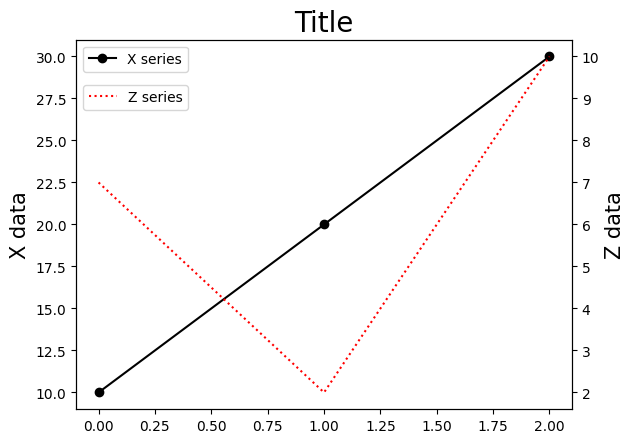
コードの説明
軸
ax1にタイトルを設定しているが、ax2でも同じ図となる。軸
ax1の縦軸(左)のラベルを設定する。軸
ax2の縦軸(右)のラベルを設定する。軸
ax1に描いたXの凡例を設定する。
legend()には引数がないのでMatplotlibが自動で凡例の位置を決める。この場合は図の左上に表示されている。軸
ax2に描いたZの凡例を設定する。
legend(loc=(0.015,0.8))には引数locがあり、凡例の位置を指定している。(0.015,0.8)の数字は図の原点を(0,0)とて左の数字はx軸、右の数字はy軸の位置を指定している。もし引数を設定しないと、Xの凡例を上書きすることになる。(0.015,0.8)のような指定方法だけではなく、他の方法もあるので参照サイトを参考にして欲しい。
日本語#
2つ方法を紹介するが、japanize_matplotlibを使う方法がより簡単であろう。
japanize_matplotlib#
使い方は到って簡単で、Pandasと同様にインポートするだけである。
import japanize_matplotlib
fix, ax = plt.subplots()
ax.plot('X', 'Y', 'r-o', data=df2)
ax.set_title('縦横タイトル', size= 30)
ax.set_xlabel('横軸', size=20)
ax.set_ylabel('縦軸', size=20)
ax.legend()
pass
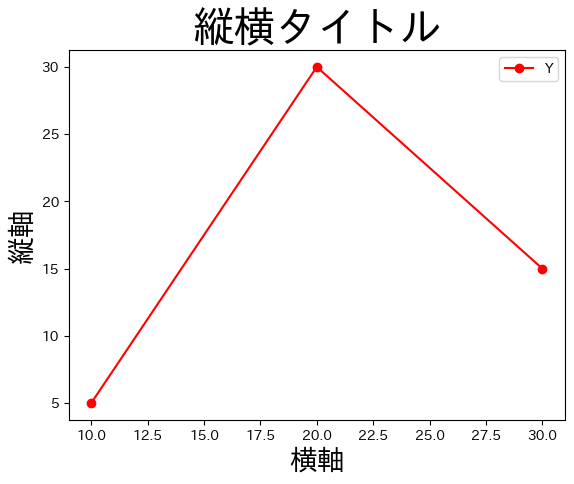
フォントを指定する#
2つの方法:
フォントはインストールせず、PC内にあるフォントを指定する。
フォントをインストールする方法
方法1の場合、以下で説明に使う変数jfontにフォントを指定する。
* Macの場合、例えばAppleGothic
* Windowsの場合、例えばYu Gothic
* この方法では一部の日本語が文字化けする場合がある。
方法2の場合:
このサイトから次の内の1つをダウンロードする。
このサイトに従ってインストールする。
次の両方もしくは1つがPCにインストールされる
IPAexMincho(IPAex明朝)
IPAexGothic(IPAexゴシック)
上の例を使い、設定方法の例を示す。
jfont = 'IPAexGothic' # (1)
fix, ax = plt.subplots()
ax.plot('X', 'Y', 'ro-', data=df2)
ax.set_title('縦横タイトル', size= 30, fontname=jfont) # (2)
ax.set_xlabel('横軸', size=20, fontname=jfont) # (3)
ax.set_ylabel('縦軸', size=20, fontname=jfont) # (4)
ax.legend(prop={'family':jfont, 'size':17}) # (5)
pass
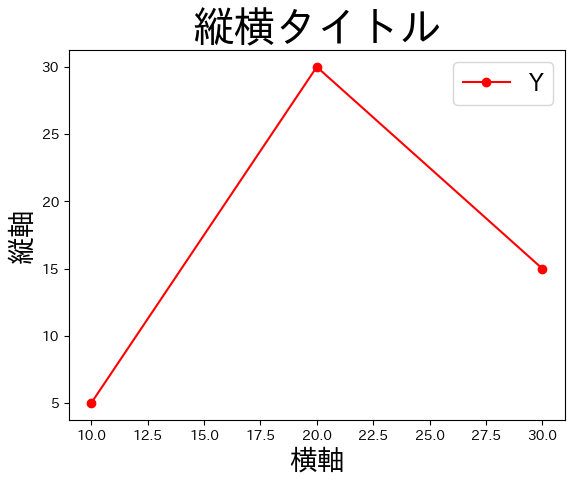
(1) 使用するフォントを
jfontに割り当てる。(2) 引数
fontnameでjfontを指定する。タイトルのフォントが変更される。(3) 引数
fontnameでjfontを指定する。横軸名のフォントが変更される。(4) 引数
fontnameでjfontを指定する。縦軸名のフォントが変更される。(5)
legendは他と設定方法が異なる。 *propはフォントのプロパティを設定する引数であり、辞書で指定する。 * キーfamilyに値jfontを指定する。凡例のフォントが変更される。 * キーsizeに数値を設定してフォントの大きさが変更される。
この例では個別にフォントを設定したが、一括で全てのフォントを変更する方法もあるが説明は割愛する。
マクロ経済学の例#
投資関数#
実質利子率rによって投資がどのように変化するかを考えてみよう。まず投資関数を次のように仮定する。
def investment(y):
return 100/(1+r)**50
100:実質利子率が0の場合の投資
実質利子率は次のリストで与えられるとする。
r_list = np.arange(0.01, 0.11, 0.01)
r_list
array([0.01, 0.02, 0.03, 0.04, 0.05, 0.06, 0.07, 0.08, 0.09, 0.1 ])
i_list = [] # 空のリスト
for r in r_list:
inv = investment(r) # 投資の計算
i_list.append(inv) # リストに追加
df_inv = pd.DataFrame({'investment':i_list, # DataFrameの作成
'interest_rate':r_list})
最初の5行を表示する。
df_inv.head()
| investment | interest_rate | |
|---|---|---|
| 0 | 60.803882 | 0.01 |
| 1 | 37.152788 | 0.02 |
| 2 | 22.810708 | 0.03 |
| 3 | 14.071262 | 0.04 |
| 4 | 8.720373 | 0.05 |
プロットしてみよう。
fix, ax = plt.subplots()
ax.plot('interest_rate', 'investment', data=df_inv)
pass
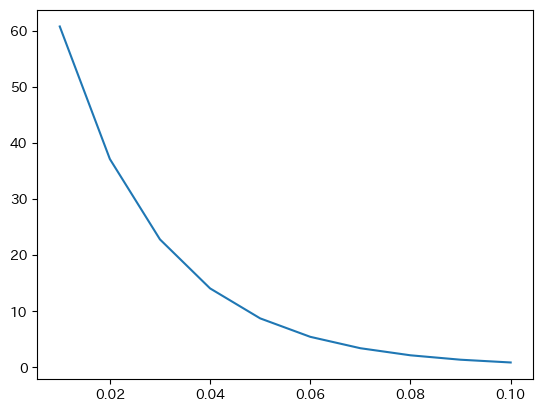
この図に次の「飾り付け」をしてみよう。
タイトル
投資関数を追加横軸ラベル
実質利子率を追加縦軸ラベル
投資を追加
将来価値#
x万円を実質年率r%の利息を得る金融商品に投資し,t年間の将来価値(期首の値)をリストで示す関数は以下で与えられた。
def calculate_futre_value(x, r, t):
value_list = [x] # 初期値が入ったリスト
for year in range(1,t+1): # 1からtまでの期間
x = x*(1+r) # 来期のxの値の計算
value_list.append(x) # リストに追加
return value_list # リストを返す
これを使い,
x=100t=30
の下で実質利子率が次のリストで与えられる値を取る場合の将来価値を図示する。
r_list = [0.01, 0.03, 0.06] # 実質利子率のリスト
dic = {} # 空の辞書
for r in r_list:
dic['r='+str(r)] = calculate_futre_value(100, r, 30) # 辞書に追加
df_future = pd.DataFrame(dic) # DataFrameの作成
dic['r='+str(r)]の説明:
str(r):r_listの要素が割り当てられるrは浮動小数点型なので関数str()を使って文字列型に変換する。'r='+str(r):文字列型のr=と文字列型のstr(r)を+で結合する。dic['r='+str(r)]:辞書dicにキー・値のペアを作成する。キー:
'r='+str(r)(文字列)値:
calculate_futre_value(100, r, 30)の返り値
最初の5行を表示する。
df_future.head()
| r=0.01 | r=0.03 | r=0.06 | |
|---|---|---|---|
| 0 | 100.000000 | 100.000000 | 100.000000 |
| 1 | 101.000000 | 103.000000 | 106.000000 |
| 2 | 102.010000 | 106.090000 | 112.360000 |
| 3 | 103.030100 | 109.272700 | 119.101600 |
| 4 | 104.060401 | 112.550881 | 126.247696 |
最後の5行を表示する。
df_future.tail()
| r=0.01 | r=0.03 | r=0.06 | |
|---|---|---|---|
| 26 | 129.525631 | 215.659127 | 454.938296 |
| 27 | 130.820888 | 222.128901 | 482.234594 |
| 28 | 132.129097 | 228.792768 | 511.168670 |
| 29 | 133.450388 | 235.656551 | 541.838790 |
| 30 | 134.784892 | 242.726247 | 574.349117 |
fix, ax = plt.subplots()
ax.plot('r=0.01', data=df_future)
ax.plot('r=0.03', data=df_future)
ax.plot('r=0.06', data=df_future)
ax.legend()
pass
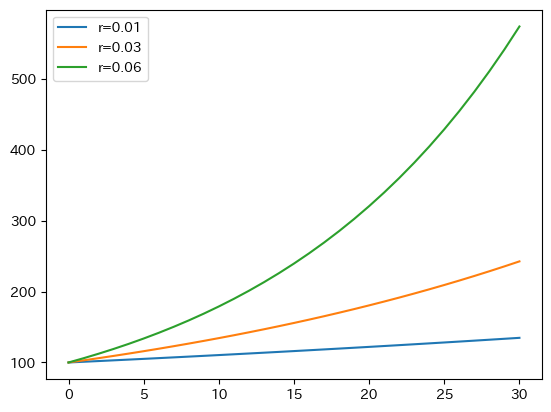
ax.plot()が続いているので、forループを使う事を推奨する。
fix, ax = plt.subplots()
for col in df_future.columns: # (1)
ax.plot(col, data=df_future)
ax.legend()
pass
(1)のdf_future.columnsについて説明すると、.columnsはデータ・フレームdf_futureの属性であり列ラベルを返す。
その他のプロット#
種類#
上で説明した図はライン・プロットと呼ばれる。Matplotlibにはその他にも様々なは種類の図を描くことができるが,以下ではライン・プロット以外に散布図とヒストグラムについて説明する。引数に関しては,上で説明したライン・プロットの引数と共通のものが多いので別に覚える必要はないが,それぞれ独自の引数もあるので基本的なものだけを取り上げることにする。
説明には次のコードで生成するDataFrameを使う。列XとYには標準正規分布(平均0,標準偏差1)から生成した100個のランダム変数が含まれている。Zには正規分布(平均2,標準偏差1)から抽出した100個のランダム変数が格納されている。
df3 = pd.DataFrame({'X':np.random.normal(size=100),
'Y':np.random.normal(size=100),
'Z':np.random.normal(loc=2, size=100)})
散布図#
基本的には次の構文となる。
fig, ax = plt.subplots() ax.scatter(<横軸のデータ>, <縦軸のデータ>)
DataFrameを使う場合は次のように書くことも可能である。fig, ax = plt.subplots() ax.scatter(<横軸の列ラベル>, <縦軸の列ラベル>, data=<DataFrame>)
df1を使って列XとYを使ってプロットしてみよう。
fig, ax = plt.subplots()
ax.scatter('X', 'Y', data=df3)
pass
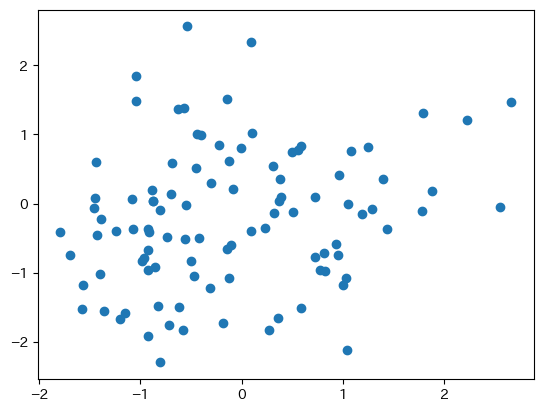
<基本的な引数>
様々な引数があり図に「飾り付け」をすることができるが,主な引数を紹介する。詳細はこのサイトを参照。
color:色(リストにして列の順番で指定する; 参照サイト)r又はred:赤k又はblack:黒g又はgreen:グリーン
marker:観測値のマーカー(o,.,>,^などがある; 参照サイト)s:マーカーの大きさ(markersizeではない!)fontsize:横軸・縦軸の数字のフォントサイズの設定label:凡例の表現を指定ax.legend()が設定されている場合のみ有効
実際に引数を指定してみよう。
fig, ax = plt.subplots()
ax.scatter('X', 'Y', data=df3,
color = 'black',
marker = 'D',
s = 20,
label= 'Xの凡例')
ax.legend()
pass
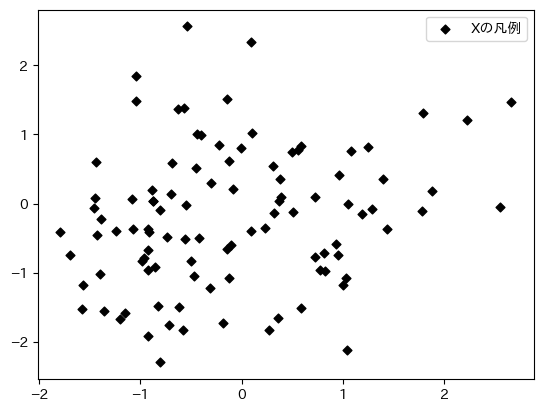
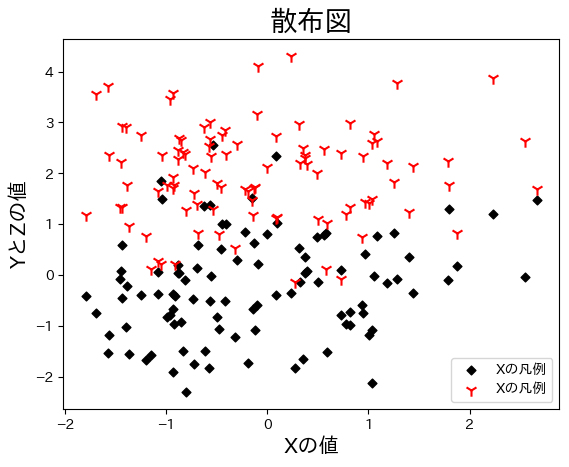
XとZの散布図を加えてタイトルなども付け加えてみよう。
fig, ax = plt.subplots()
ax.scatter('X', 'Y', data=df3,
color = 'black',
marker = 'D',
s = 20,
label= 'Xの凡例')
ax.scatter('X', 'Z', data=df3,
color = 'red',
marker = '1',
s = 80,
label= 'Xの凡例')
ax.legend()
ax.set_title('散布図', size=20)
ax.set_xlabel('Xの値', size=15)
ax.set_ylabel('YとZの値', size=15)
pass
ヒストグラム#
基本的には次の構文となる。
fig, ax = plt.subplots() ax.hist(<データ>)
DataFrameを使う場合のように書くことも可能である。fig, ax = plt.subplots() ax.scatter(<列ラベル>, data=<DataFrame>)
df3の列Xを使ってプロットしてみよう。
fig, ax = plt.subplots()
ax.hist('X', data=df3)
pass
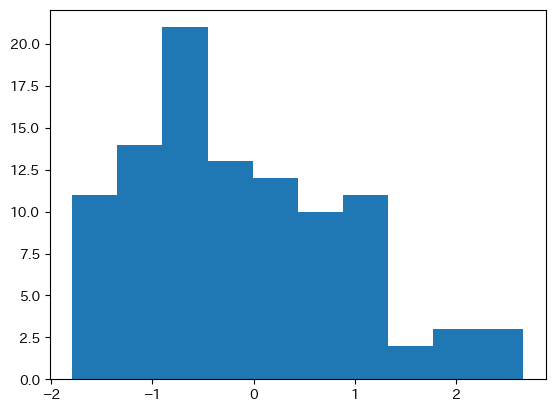
<基本的な引数>
様々な引数があり図に「飾り付け」をすることができる。詳しくはこのリンクを参照することにして,ここでは基本的な引数だけを紹介する。
bins:柱の数linewidth又はlw:柱の間隔(デフォルトは1)color:色(リストにして列の順番で指定する; 参照サイト)r又はred:赤k又はblack:黒g又はgreen:グリーン
edgecolor又はec:柱の境界線の色alpha:透明度(0から1.0; デフォルトは1)density:縦軸を相対度数にする(デフォルトはFalse)全ての柱の面積の合計が
1になるように縦軸が調整される。1つの柱の高さが1よりも大きくなる場合もある。
label:凡例の表現を指定ax.legend()が設定されている場合のみ有効
上のヒストグラムに引数をしてしてみよう。
fig, ax = plt.subplots()
ax.hist(df3['X'],
color='green',
bins = 20,
ec='white',
lw=3,
density=True)
pass
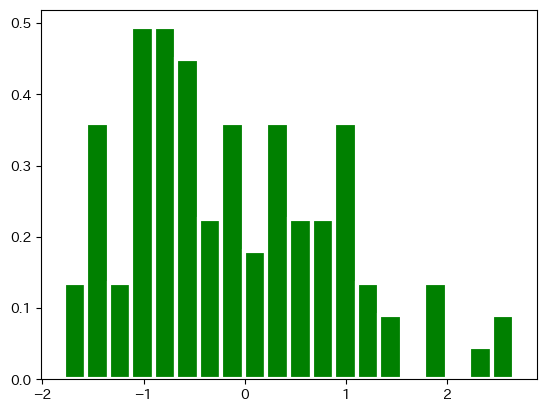
次に複数のデータを並べてプロットする場合を考えよう。方法は簡単で,異なるデータをリストとして指定すれば良い。
fig, ax = plt.subplots()
ax.hist([df3['X'],df3['Z']],
bins = 20,
color = ['black','red'],
ec='black',
label=['Xの凡例','Yの凡例'])
ax.legend()
ax.set_title('ヒストグラム', size=20)
pass
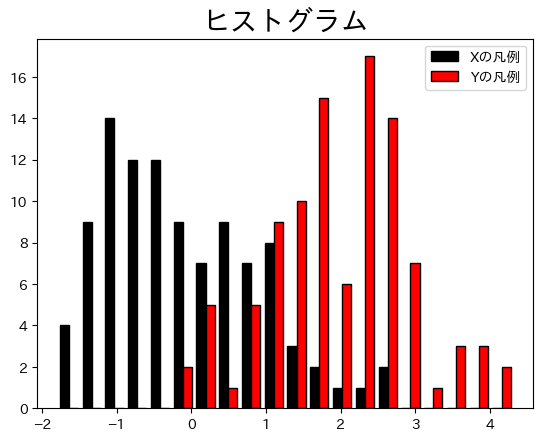
上のコードに引数stacked=Trueを加えると,柱を重ねて表示される。試してみよう。またax.hist()を2回使うと,2つのヒストグラムを重ねて表示することができる。この場合,引数alphaの値を調整すると良いだろう。
fig, ax = plt.subplots()
ax.hist(df3['X'],
bins = 20,
color = 'black',
ec='black',
alpha=0.5,
label='Xの凡例')
ax.hist(df3['Z'],
bins = 20,
color = 'red',
ec='black',
alpha=0.5,
label='Zの凡例')
ax.legend()
ax.set_title('ヒストグラム', size=20)
pass
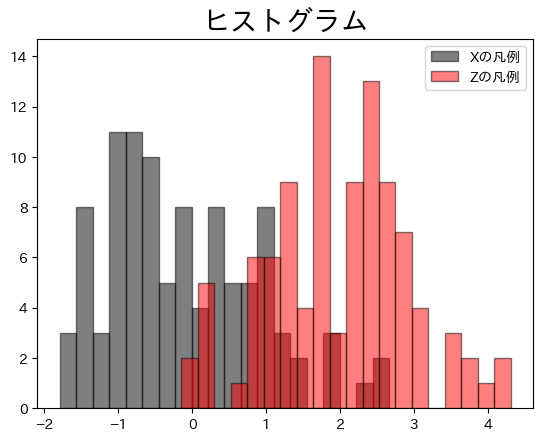
濃い赤の部分が重なっている部分となる。
ヒストグラムは縦軸に度数,横軸に階級を取ったグラフだが,関連する手法にカーネル密度推定と呼ばれるものがある。考え方は簡単で,上のようなヒストグラムのデータに基づき面積が1になるようにスムーズな分布を推定する手法である。残念ながらMatplotlibにはカーネル密度推定プロットのメソッドは実装されていない。しかしDataFrameのメソッドplot()を使えば簡単に描くことが可能である。興味がある読者はこのセクションを参考にしてはどうだろう。
縦線・横線#
図に縦線や横線を追加したい場合がある。その場合は,他の図と同じように「軸」に追加していく事になる。次のような書き方となる。
縦線の場合
ax.axvline(<横軸の値>)
ここで
axvlineのaxはAXis,vはVertical,lineはLINEのことを表している。横線の場合
ax.axhline(<縦軸の値>)
ここで
axhlineのaxはAXis,hはHorizontal,lineはLINEのことを表している。
ここでaxは.subplots()で返された「軸」のことである。
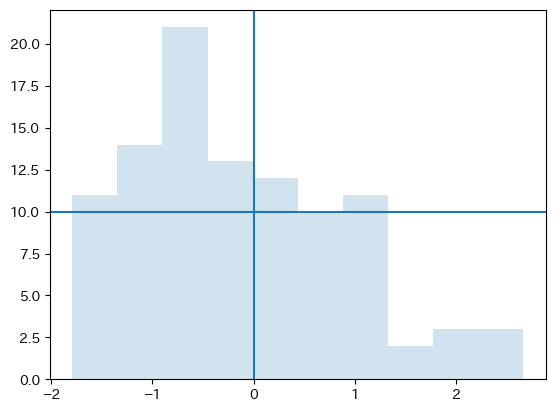
ヒストグラムを使ってプロットしてみよう。
fig, ax = plt.subplots()
ax.hist(df3['X'], alpha=0.2)
ax.axhline(10)
ax.axvline(0)
pass
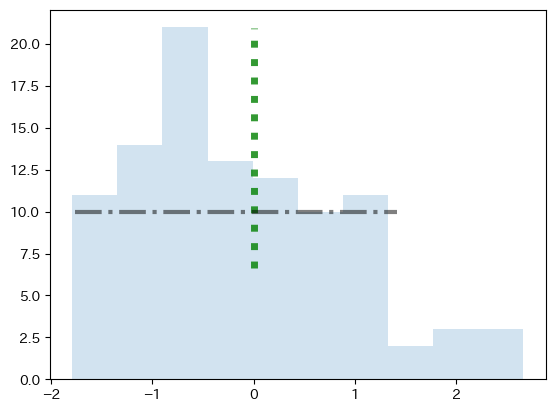
<基本的な引数>
様々な引数があり図に「飾り付け」をすることができる。詳しくはこのリンクとこのリンクを参照することにして,ここでは基本的な引数だけを紹介する。
ymin:axvlineの縦軸における最小値(0~1の値; デフォルト0)ymax:axvlineの縦軸における最大値(0~1の値; デフォルト1)xmin:axhlineの横軸における最小値(0~1の値; デフォルト0)xmax:axhlineの横軸における最大値(0~1の値; デフォルト1)linestyle:線のスタイル(リストにして列の順番で指定する;-``--``-.``:)linewidthorlw:線の幅color:色(リストにして列の順番で指定する; 参照サイト)rは赤kは黒gはグリーン
alpha:透明度(0から1.0; デフォルトは1)
fig, ax = plt.subplots()
ax.hist(df3['X'], alpha=0.2)
ax.axvline(0,
ymin=0.3,
ymax=0.95,
linestyle=':',
linewidth=5,
color='g',
alpha=0.8)
ax.axhline(10,
xmin=0.05,
xmax=0.7,
linestyle='-.',
linewidth=3,
color='k',
alpha=0.5)
pass
棒グラフ#
まず次のコードでデータを準備しよう。
df4 = pd.DataFrame({'country':['A','B','C'],
'gdp':[100,90,110],
'con':[50,60,55],
'inv':[15,10,20],
'gov':[10,5,30],
'netex':[25,15,5]})
df4
| country | gdp | con | inv | gov | netex | |
|---|---|---|---|---|---|---|
| 0 | A | 100 | 50 | 15 | 10 | 25 |
| 1 | B | 90 | 60 | 10 | 5 | 15 |
| 2 | C | 110 | 55 | 20 | 30 | 5 |
3国のGDPとその構成要素からなるDataFrameである。
country:国gdp:GDPcon:消費inv:投資gov:政府支出netex:純輸出
このDataFrameを使って棒グラフの作成方法を説明するが,次の構文となる。
fig, ax = plt.subplots() ax.scatter(<横軸の列ラベル>, <縦軸の列ラベル>, data=<DataFrame>)
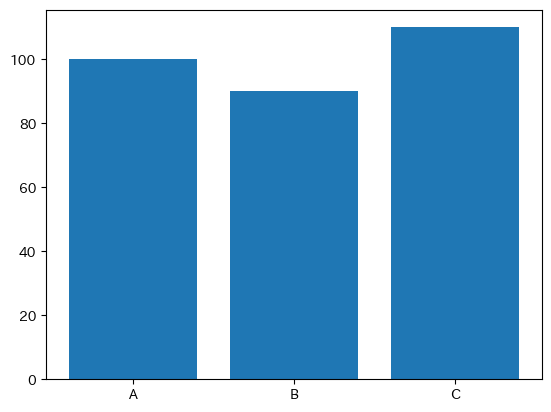
まずA国のgdpの棒グラフを表示してみよう。
fig, ax = plt.subplots()
ax.bar('country','gdp', data=df4)
pass
<基本的な引数>
詳しい引数についての説明はこのリンクを参照することにして,ここでは基本的な引数だけを紹介する。
width:棒の幅(デフォルトは0.8)bottom:縦軸での棒の基点(デフォルトは0)color:色(リストにして列の順番で指定する; 参照サイト)r又はred:赤k又はblack:黒g又はgreen:グリーン
edgecolor又はec:柱の境界線の色linewidth又はlw:柱の境界線の幅alpha:透明度(0から1.0; デフォルトは1)label:凡例の表現を指定ax.legend()と一緒に使う。
これらの引数を使いプロットしてみよう。
fig, ax = plt.subplots()
ax.bar('country','gdp', data=df4,
width=0.5,
color='green',
ec='black',
linewidth=5,
alpha=0.5,
label='GDP')
ax.legend()
ax.tick_params(axis='both', labelsize=15)
pass
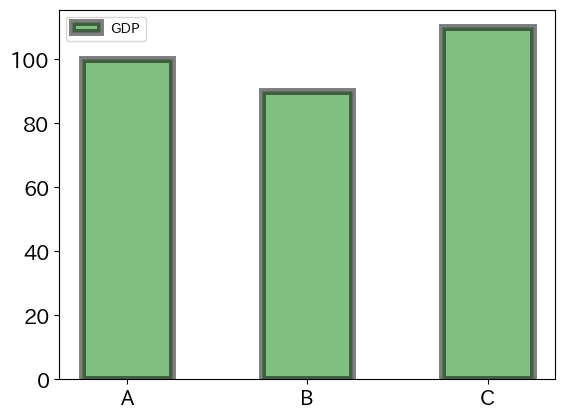
ax.tick_params()は縦軸と横軸の文字の大きさを調節している。
次に複数の列データを表示する場合を考えてみよう。まず単に軸にデータを追加する場合を考えてみる。
fig, ax = plt.subplots()
ax.bar('country','con', data=df4, label='消費')
ax.bar('country','inv', data=df4, label='投資')
ax.legend()
pass
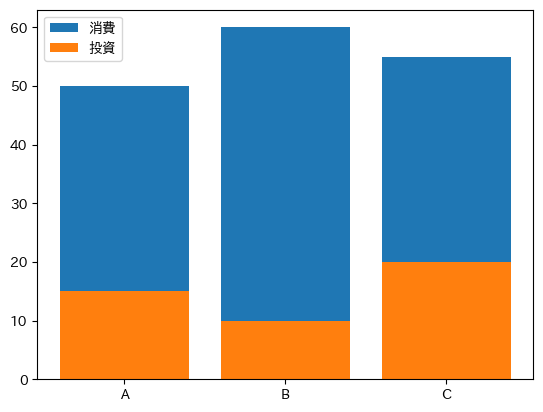
縦軸を確認するとわかるが,まず消費(con)の棒がプロットされ,それに投資(ivn)の棒が重ねてプロットされている。これは引数base(縦軸における棒の基点)がデフォルトの0に設定されており,消費も投資も0から始まっているためである。この点を踏まえ,棒を積み上げる場合を考えよう。その場合,投資のbaseは消費の高さになる必要がある。また政府支出を積み上げる場合は,積み上がった消費の高さが政府支出の基点になる必要がある。純輸出を積み上げる場合も同様に考える必要がある。この点に注意して棒を積み上げるには次のようなコードとなる。
base = df4.iloc[:,2:].cumsum(axis='columns') # (1)
base = base - df4.iloc[:,2:] # (2)
var_list = df4.columns[2:] # (3)
leg_list = ['消費','投資','政府支出','純輸出'] # (4)
fig, ax = plt.subplots()
for v, l in zip(var_list, leg_list):
ax.bar('country', v, data=df4,
label=l,
bottom=base.loc[:,v]) # (5)
ax.plot('gdp', data=df4, # (6)
color='black',
marker='o',
label='GDP')
ax.legend()
pass
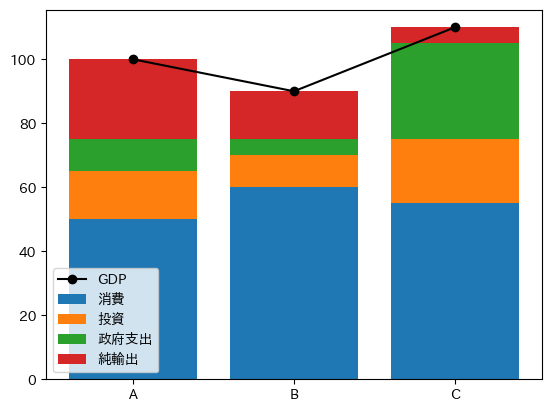
(1)〜(2)で棒の基点となる値をDataFrameとして計算し,それを(5)で使っている。(3)〜(4)行目はforループに使うイタラブルを作成している。また(6)では列gdpのライン・プロットを追加している。コードを見るとわかるように,少々複雑である。よりシンプルなコードで同じ図を描きたい場合は,ここで説明しているDataFrameのメソッドplot()を参考にすると良いだろう。その方法では(1)〜(2)を自動計算するため引数baseの値を考える必要がない。
次に,複数の棒(データ)を横に並べたい場合を考えてみよう。主に次の2つの点でコードが少々複雑になってしまう。
引数
widthを使い,棒の横の位置を調整する必要がある。国名
A,B,Cの位置を調整する必要がある。
この2点を考慮すると次のコードとなる。
idx = df4.index # (1)
wd = 1/5 # (2)
x_ticks = df4.loc[:,'country'] # (3)
fig, ax = plt.subplots(figsize=(8,4))
for i, (v, l) in enumerate(zip(var_list, leg_list)):
ax.bar(idx+wd*(i+1), # (4)
v,
data=df4,
label=l,
width=wd) # (5)
ax.legend()
ax.set_xticks(idx+wd*2.5, # (6)
x_ticks, # (7)
fontsize=15) # (8)
pass
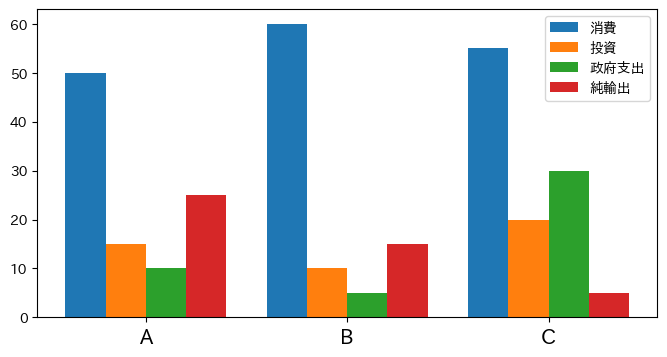
簡単にコードを説明する。
(1)
df4の行インデック(番号)をidxに割り当てる。これを図の横軸に使う。そのままでは国名が表示されないので,(7)で設定することになる。(2) 棒の幅を
1/5としてwdに割り当てる。(3) 国名を
x_ticksに割り当てる。(7)で使うことになる。(4) 棒の横軸の位置を指定する。ループが実行されるごとに表示される棒は
wdだけ右にシフトすることになる。(5) 棒の幅を
wdにする。(6) 横軸の目盛の位置を指定する。
(7) 横軸の目盛ラベルを国名
x_ticksとする。(8) 目盛ラベルのフォントの大きさを指定する。
よりシンプルなコードで同じ図を書きたい場合は,ここで説明しているDataFrameのメソッドplot()を使う方法を利用しても良いだろう。