図示とシミュレーション#
import random
import numpy as np
import matplotlib.pyplot as plt
from py4macro import xvalues
# 警告メッセージを非表示
import warnings
warnings.filterwarnings("ignore")
ここでの目的は2つある。第1に,Matplotlib(「マットプロットリブ」と読む)はプロットのための代表的なパッケージであり,外部パッケージとしてはMatplotlibのみを使い(PandasやNumpyは使わない)データを図示(プロット)する方法を解説する。第2に,統計学の重要な概念をシミュレーションをおこない,データを可視化し理解を深めることである。
Matplotlibは大きなパッケージであり,その中にあるpyplotモジュールを使うことになる。慣例に沿ってpltとしてインポートしている。
ライン・プロット#
説明#
次がプロットする際の構文である。
plt.plot(<x軸の値>,<y軸の値>)
実際にプロットするために次の値を設定しよう。
x = [1,2,3]
y = [10,30,20]
引数にxとyを指定するとプロットできる。
plt.plot(x, y, marker='o')
[<matplotlib.lines.Line2D at 0x10f17c410>]
コードにmarker='o'が追加されているが,「●」を表示するために使っている。このような引数の使い方は後で詳しく説明するので,ここでは気にしないで読み進めて欲しい。
「●」のマーカーがある点がxとyの値の組み合わせとして表示されている。
左下の「●」の座標は
xとyの0番目の値であるx=1とy=10となる。中央上の「●」の座標が
xとyの1番目の値であるx=2とy=30となる。右端の「●」はの座標が
xとyの2番目の値であるx=3とy=20となる。
plot()はデフォルトでそれらの点を直線で結んでおり,ライン・プロットと呼ばれる。曲線を描くには,単に座標の点を増やすことによりスムーズな曲線を表示することが可能となる。言い換えると,短い直線を使うことにより曲線を描画することになる。
値の生成#
曲線を描画するためには座標の数を増やす必要がある。ここでは,そのためのコードを考える。
x軸の値#
まずx軸の複数の値が要素となるリストを作成するが,ここではpy4macroモジュールに含まれるxvalues()関数を使う。以前も説明したが,関数の引数などを確認したい場合はhelp()関数を使うことで調べることができることを思いだそう。
help(xvalues)
Help on function xvalues in module py4macro.py4macro:
xvalues(l, h, n)
引数
l:最小値(lowest value)
h:最大値(highest value)
n:作成する数値の数を指定する(正の整数型,number of values)
戻り値
n個の要素から構成されるリスト
例えば,次の値を使って,リストを作成してみよう。
l = 1
h = 2
n = 3
xvalues(1,2,3)
[1.0, 1.5, 2.0]
この例では,1から2の間の値3個をリストの要素として生成している。
次の例では,-1から1の間で5の値をからなるリストを作成する。
x = xvalues(-1, 1, 5)
x
[-1.0, -0.5, 0.0, 0.5, 1.0]
y軸の値#
y軸の値は,描きたい関数に依存している。例えば,次の2次関数をプロットしたいとしよう。
まず最初にこの関数を捉えるPythonの関数を作成する。
def quadratic(x):
return x**2
次に,xの値を使い内包表記でyの値から構成されるリストを作成する。
y = [quadratic(i) for i in x]
y
[1.0, 0.25, 0.0, 0.25, 1.0]
曲線のプロット#
上で作成したxとyを使いプロットしよう。
plt.plot(x, y, marker='o')
[<matplotlib.lines.Line2D at 0x110fcf2c0>]
座標の数が少ないのでスムーズな曲線には見えない。もっと座標を増やしてみよう。
x = xvalues(-1, 1, 200)
y = [quadratic(i) for i in x]
plt.plot(x, y)
[<matplotlib.lines.Line2D at 0x1110e9430>]
\(y=x^2\)の図らしく見える。
Hint
上の2つの図の上に文字が表示されている。plt.plot(x,y)はあるオブジェクトを返しており,それが文字として表示されている。表示を消すには,次の方法のどれかを使えば良いだろう。
plt.plot(x,y)の次の行にpassもしくはplt.show()と書く。最後の行に
;を付け加える。例えば,plt.plot(x,y);。最後の行を
_ = plt.plot(x,y)とする。これは,返されるオブジェクトを変数_に割り当てることにより表示を消している。もちろん_でなくても良いが,重要でないオブジェクトには_がよく使われる。
重ねてプロット#
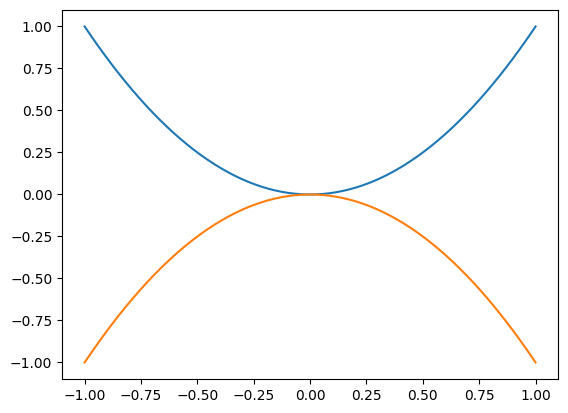
2つのyの値を生成しよう。
y0 = [quadratic(i) for i in x]
y1 = [-quadratic(i) for i in x]
y0はyと同じであり,y1は単にマイナスの符号ついた関数の値である。この2つの関数を重ねてプロットしたいとしよう。コードは簡単で同じplt.plot()をリピートするだけである。
plt.plot(x, y0)
plt.plot(x, y1)
pass
plot()の基本的な引数#
plot()に引数を使うことによりデータの表示方法を指定できる。詳しくはこのリンクを参照することにして,ここでは基本的な引数だけを紹介する。
linestyle:線のスタイル(リストにして列の順番で指定する;-,--,-.,:などがある)linewidthorlw:線の幅colororc:色(参照サイト)r又はredは赤k又はblackは黒g又はgreenはグリーン
marker:観測値のマーカー(o,.,>,^などがある; 参照サイト)markersize:マーカーの大きさlabel:以下で説明するplt.legend()がある場合に有効となる
plt.plot([1,2,3], [10,30,25],
linestyle=':',
linewidth=2,
color='r',
marker='o',
markersize=10)
plt.plot([1,2,3], [30,10,15],
linestyle='-',
linewidth=2,
color='k',
marker='^',
markersize=10)
pass
引数をいちいち書くのが面倒な場合、次の3つを簡略して一緒に指定できる。
linestylecolormarker
例えば、
linestyle=':'color='red'marker='o'
の場合、:roと書くことができる。
plt.plot([1,2,3], [10,30,25], ':ro')
pass
(注意点)
:roは文字列:,r,oの順番を変えても良い。:や:oのように1つもしくは2つだけを指定しても良い。:roは=を使う引数の前に置く。
詳細は参考サイト(英語)を参照。
その他の「飾り付け」#
次の5つはplt.plot()の下に付け加えることによって表示できる。
plt.title():タイトルを設定する。文字列で指定し、大きさは引数
sizeで指定する。
plt.xlabel():横軸ラベル文字列で指定し、大きさは引数
sizeで指定する。
plt.ylabel():縦軸ラベル文字列で指定し、大きさは引数
sizeで指定する。
plt.legend():凡例を表示する。plot()の引数labelを使って表示する文字列を指定する。fontsize:フォントの大きさを指定する。
plt.grid():グリッド線が表示される。
plt.plot([1,2,3], [10,30,25], ':ro', label='This is a legend')
plt.title('This is a Title', size=30)
plt.xlabel('Label for x', size=20)
plt.ylabel('Label for y', size=20)
plt.legend(fontsize=20)
plt.grid()
pass
最後に,図の大きさの指定方法を例を使って説明しよう。変更方法は簡単で,次の行をplt.plot()の上に付け加えるだけである。
plt.figure(figsize=(7,3))
この例では,横の長さを7,縦の長さを3に指定している(単位はインチ)。デフォルトの値は(6.4, 4.8)である。このコードの意味を簡単に説明しよう。
plt.figure()は透明のキャンバスを作成する。引数
figsize=(8,4)は,そのキャンバスのサイズを指定する。透明のキャンバス上に,
plt.plot()は図をプロットすることになる。従って,plt.plot()はplt.figure()の後に書く必要がある。
plt.figure(figsize=(7,3))
plt.plot([1,2,3], [10,30,25], ':ro', label='This is a legend')
plt.title('This is a Title', size=30)
plt.xlabel('Label for x', size=20)
plt.ylabel('Label for y', size=20)
plt.legend(fontsize=20)
plt.grid()
pass
Note
このままで日本語を表示できない。一番簡単な方法は外部パッケージのjapanize_matplotlibを使うことだろう。
import japaneze_matplotlib
一方,現時点でjapanize_matplotlibはJupyterLiteに対応していないため,JupyterLiteを使う場合は,次のようにjapanize_matplotlib_jliteを使うようにしよう。
import piplite
awaite piplite.install('japanize_matplotlib_jlite')
import japaneze_matplotlib_jlite
ヒストグラム#
基本的には次の構文となる。
plt.hist(<データ>)
まず標準正規分布からランダム変数を10,000個抽出して変数z0に割り当てよう。
z0 = [random.gauss(0,1) for _ in range(10_000)]
このデータのヒストグラムを表示してみよう。
plt.hist(z0)
pass
<基本的な引数>
様々な引数があり図に「飾り付け」をすることができる。詳しくはこのリンクを参照することにして,ここでは基本的な引数だけを紹介する。
bins:階級の数(柱の数)整数型を使えば文字通りの柱の数となる。
区間の値をリストとして設定することができる。例えば,
0と1を等区間に柱を2つ設定する場合は[0, 0.5, 1]となる。
linewidth又はlw:柱の間隔(デフォルトは1)color:色(リストにして列の順番で指定する; 参照サイト)r又はred:赤k又はblack:黒g又はgreen:グリーン
edgecolor又はec:柱の境界線の色alpha:透明度(0から1.0; デフォルトは1)density:縦軸を相対度数にする(デフォルトはFalse)全ての柱の面積の合計が
1になるように縦軸が調整される。1つの柱の高さが1よりも大きくなる場合もある。
label:凡例の表現を指定ax.legend()が設定されている場合のみ有効
上のヒストグラムに引数をしてしてみよう。
plt.hist(z0,
bins = 30,
lw=2,
color='green',
ec='white',
# alpha=0.5,
# label='values of z'
density=True)
pass
次に複数のデータを重ねてプロットする場合を考えよう。方法は簡単で,ライン・プロットと同じようにplt.hist()を続けてコードを書くだけである。まず平均4標準偏差2の正規分布からのランダム変数を用意しよう。
z1 = [random.gauss(5,2) for _ in range(10_000)]
z0とz1のヒストグラムを重ねて表示しよう。
plt.hist(z0,
bins = 30,
color='red',
ec='white',
alpha=0.5)
plt.hist(z1,
bins = 30,
color='black',
ec='white',
alpha=0.5)
pass
濃い赤の部分が重なっている部分となる。
その他の「飾り付け」(タイトルなど)はライン・プロットと同じとなる。
plt.hist(z0,
bins = 30,
color='red',
ec='white',
alpha=0.5,
label='z0')
plt.hist(z1,
bins = 30,
color='black',
ec='white',
alpha=0.5,
label='z1')
plt.title('This is a Title', size=30)
plt.xlabel('Label for x', size=20)
plt.ylabel('Label for y', size=20)
plt.legend(fontsize=20)
plt.grid()
pass
大数の法則#
大数の法則とは#
母集団のパラメータを次の様に表記しよう。
\(\mu\):平均
この母集団から標本\(X_1,X_2\cdots X_n\)を抽出し(\(n\)は標本の大きさ),その平均を\(\overline{X}_n\)とする。
この式の意味を確認するために,例として,通常のサイコロを投げて出た目の平均を考えてみよう。\(i\)回目に投げた結果を\(X_i\),\(i=1,2,..,n\)で表すと,\(\overline{X}_n\)は\(n\)回投げた目の平均ということになる。実際に,サイコロを投げて計算してみよう。サイコロを\(n=3\)回投げると\(\{5,1,3\}\)が出たので,\(\overline{X}_3=3\)になった。次に,追加的にもう一回サイコロを投げると\(6\)が出たので,出た目は\(\{5,1,3,6\}\)となり,平均は\(\overline{X}_4=3.75\)になった。この様に,サイコロを投げる回数を増やすと,平均も変化することになる。
この点を念頭に,同じ試行を数多く繰り返した場合の結果に関する法則を紹介する。
<大数の法則(Law of Large Numbers)>
母集団の分布がどのようなものであれ(連続型,離散型),\(\mu\)が有限である限り,\(n\)が大きくなると\(\overline{X}_n\)は\(\mu\)に近づいていく。
(2)#\[\lim_{n\rightarrow\infty}\overline{X}_n\;\rightarrow\;\mu\]
サイコロをもう一度考えてみよう。サイコロを投げる回数を増やしていくと,投げた目の平均は\(3.5\)に近づいて行くという事である。出るサイコロの目はランダム変数なので,下のシミュレーションで確認するように,式(2)は誤差の絶対値\(|\overline{X}_n-\mu|\)の単調減少を意味している訳ではない事に注意しよう。
実社会とどの様な関係があるのだろうか。ビジネスの中で直接関係するのは保険業だ。自動車事故を考えてみよう。個々人にしてみれば,交通事故に遭うと大変だが,滅多に起こらない。一方,保険会社からすると,多くの個人・企業と契約しているため,交通事故は日常茶飯事となる。この例を考えるために,自動車免許を持つ人を母集団とし,その人数を\(N\)としよう。ここで\(N\)は非常に大きな数となる(日本の場合は約8,200万人)。また,1年間でドライバーが交通事故に遭遇する確率を\(\mu\)とし,全てのトライバーにとって\(\mu\)は同じと想定する。更に,トライバー\(j\)に事故が発生すると\(X_j=1\),発生しない場合は\(X_j=0\)とし,\(\sum_{j=1}^NX_j\)は事故の発生回数となる。母集団での事故の平均発生回数を\(\dfrac{\sum_{j=1}^NX_j}{N}=\mu\)とすると,\(\mu\)は母集団の中で事故に遭遇するトライバーの割合と等しいことになる。ここまでは母集団の話であり,次はある保険会社を考えよう。母集団の内,ドライバー\(i=1,2,3,...n\)が保険会社Aと自動車保険を契約したとする。\(n\)は母集団から「抽出」された顧客の総数となり,\(n<N\)である。ここで,事故の平均発生回数は式(1)と同じ\(\overline{X}_n\)となり,\(\overline{X}_n\)は事故に遭遇する顧客の割合と等しい。ここで重要な点は,\(\overline{X}_n\)はランダム変数であり,必ずしも\(\overline{X}_n=\mu\)とはならない,ということである。例えば,\(n=10\)の場合を想像すると,直感的にも理解できるだろう。従って,母集団の\(\mu\)が既知だとしても,保険会社Aにとって事故に遭う顧客数は毎年変化する。その変化が大きいと,保険金支払いの変動幅が大きくなり,ビジネスに支障をきたすことになるかも知れない。しかし,顧客数\(n\)が十分に大きいと,式(2)が成立する。即ち,事故に遭う顧客の割合\(\overline{X}_n\)は,事故の確率\(\mu\)に近づくことになり,毎年の\(\overline{X}_n\)の変化が小さくなる。将来の\(\overline{X}_n\)を予測しやすくなり,それに従って保険料を決めればビジネスが成り立つことになる。もちろん,現実はこれより複雑だが,保険業の基本的なアイデアは大数の法則に基づいている。
コイントス#
この節と次の節の目的は,コイントスのシミュレーションを使い大数の法則を理解することである。コインの表を1,裏を0とするコイントスを考えよう。1と0はそれぞれ確率\(0.5\)で発生するベルヌーイ分布に従うと仮定する。従って,以下が成り立つ。
平均:\(\mu=0.5\times 1 +0.5\times 0 = 0.5\)
この様なランダム変数は既出の次の関数で表すことができる。
random.randint(0,1)
0
この関数を実行する度に異なる値(0又は1)が発生することになる。
次に,20個のコインを同時に投げる場合を考えよう(1個のコインを20回投げても同じ)。この場合の20が標本の大きさであり,変数n(number of coins)に割り当てよう。
n = 20
標本の大きさがnの場合の結果は,次の内包表記を使うと簡単に生成することができる。
toss = [random.randint(0,1) for _ in range(n)]
toss
[1, 0, 0, 1, 0, 0, 0, 0, 1, 0, 1, 1, 0, 0, 1, 0, 0, 1, 0, 0]
1(表)が何回発生したかを数えてみよう。この場合,sum()関数を使うことができる。
sum(toss)
7
もしくは,メソッドであるcount()を使うこともできる。引数の値に1を指定すると1の数を返すことになる。
head = toss.count(1)
head
7
この結果を利用すると平均は次のように計算できる。
head / n
0.35
この値は上のコードを実行する度に異なる値になる。理論的な平均0.5と同じ場合もあれば,そうでない場合もある。
シミュレーション#
上の説明では同時にトスするコインの数をn=20として計算したが,ここではn=1からn=200までの値を使って平均を計算する。基本的には,上のコードを再利用して,forループとしてまとめることにする。
mean_list = [] #1
for n in range(1,200+1): #2
toss = [random.randint(0,1) for _ in range(n)] #3
mean = sum(toss) / n #4
mean_list.append(mean) #5
<コードの説明>
#1:forループで計算する平均を格納するリスト。#2:range(1,200+1)となっている。1枚のコインから200枚のコインまでのループ計算となっている。#3:n枚のコインを投げた場合の結果を変数tossに割り当てる。#4:平均を計算し変数meanに割り当てる。#5:meanをmean_listに追加する。
mean_listをプロットしてみよう。
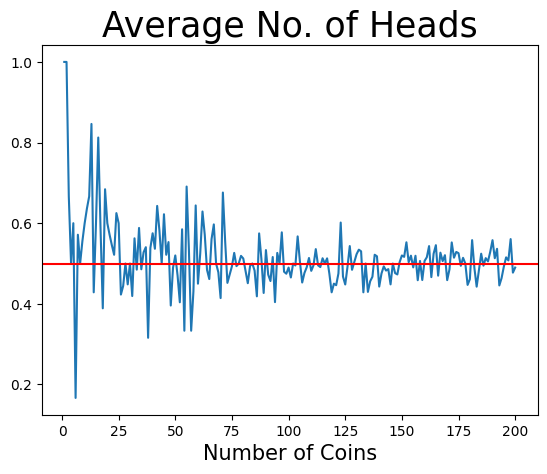
plt.plot(range(1,200+1), mean_list) #1
plt.title('Average No. of Heads', size=25) #2
plt.xlabel('Number of Coins', size=15) #3
plt.axhline(0.5, color='red') #4
pass
<コードの説明>
#1:ライン・プロットで描画する。x軸にrange(1,200+1)を使っており,自動的にlist(range(1,200+1))として扱っている。またrange(1,200+1)を省いてplt.plot(mean_list)としても図は表示される。その場合,x軸にはmean_listのインデックス番号が使われることになり,xの値は0から199となる(図では分かりづらいが)。#2:タイトルの設定。フォントサイズは25。#3:x軸のラベルの設定。フォントサイズは15。#4:plt.axhline()は横線を引く関数。引数はy軸の値(0.5),色は赤を指定。
この図から標本の大きさ(同時に投げるコインの数)であるnが増えると,平均は理論値0.5に収束していることが確認できる。
中心極限定理#
中心極限定理とは#
母集団(大きさが無限)のパラメータを次の様に表記しよう。
\(\mu\):平均
\(\sigma\):標準偏差
この母集団の分布は不明と仮定する。次に,この母集団から標本\(X_1,X_2\cdots X_n\)を抽出し(\(n\)は標本の大きさ),その平均を\(\overline{X}\)とする。
この式の意味を再度確認するために,例として,通常のサイコロを投げて出た目の平均を考えてみよう。ここでも実際に,サイコロを投げた結果を書いてみる。サイコロを\(n=6\)回投げると,\(\{3,1,3,6,2,2\}\)が出たので,\(\overline{X}_6=2.8\dot{3}\)になった。次に,もう一度サイコロを\(n=6\)回投げると,\(\{2,6,1,2,4,3\}\)が出て,\(\overline{X}_5=3\)となった。要するに,\(n=6\)回サイコロを投げる度に,出る目は異なり,平均も異なる事になる。その意味では,平均\(\overline{X}_n\)自体もランダム変数である。
更に,標準化した平均を次の様に定義しよう。
ここで\(Z_n\)は平均0,分散1となるランダム変数である。この段階でも,\(Z_n\)の分布型は不明のままである。しかし,しかしである。
<中心極限定理(Central Limit Theorem)>
母集団の分布がどのようなものであれ(連続型,離散型),\(\mu\)と\(\sigma\)が有限である限り,\(n\)が大きくなると\(Z_n\)の分布は標準正規分布\(N(0,1)\)に近づいていく。
「えっ!マジ😱」と思うような結果ではないだろうか。
式(3)の説明
式(3)は,ランダム変数の標準化の式であり,次の式に基づいている。
\(Y\):ランダム変数
\(E[Y]\):\(Y\)の平均
\(\text{Var}[Y]\):\(Y\)の分散
\(\sqrt{\text{Var}[Y]}\):\(Y\)の標準偏差
\(Z\):\(Y\)を標準化したランダム変数
\(Y=\overline{X}_n\)とすると,\(\text{E}[Y]\)は次のように計算できる。
\(\text{Var}[Y]\)も次のように計算できる。
従って,
これらの結果を使って計算したのが,式(3)となる。「?」と思う人は,統計学の教科書もしくは講義ノートを確認してみよう。
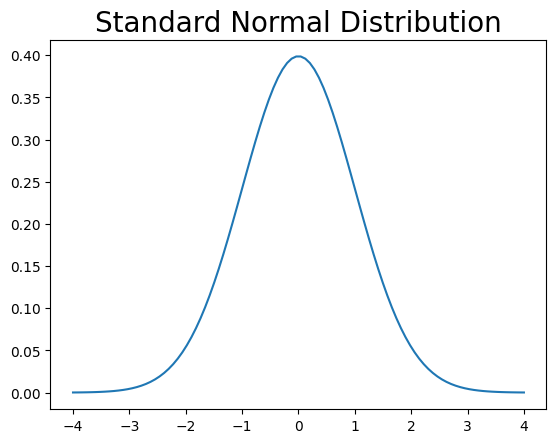
下の図は標準正規分布をプロットしている。左右対称のベル型の分布であり,横軸の値は\(-\infty\)から\(\infty\)まで全ての実数をカバーしている。
Show code cell source
def plot_normal():
from scipy.stats import norm
x = xvalues(-4,4,100)
plt.plot(x, norm.pdf(x,0,1))
plt.title('Standard Normal Distribution', size=20)
return plt.show()
plot_normal()
この驚くべき結果は統計学の金字塔である。ではどこが金字塔なのだろうか。データ分析のためには標本を集める必要がある。例えば,大学生の1日の授業以外の勉強時間(単位は分)を考えてみよう。マイナス時間や24時間以上はあり得ないため,母集団の分布は正規分布ではないことは明らかである。標本の中には驚くほど勉強している人もいれば,アルバイトなどに追われ0分の学生も含まれるかも知れない。もしかすると,分布には複数のピークがあるかもしれない(例えば,0と60分)。いずれにしろ,母集団の分布は未知であるため,仮説検定は不可能のように感じられる。しかし中心極限定理は,超えることはできないように見える壁をいとも簡単に飛び越えさせてくれる。ランダム標本を集め,標本の大きさが十分に大きければ,標本平均は正規分布に従う(近似される)ため仮説検定が可能になるのだ。
ここでの目的は,シミュレーションを使って中心極限定理を視覚的に理解・確認することである。コイントスの例を使い,次のステップで進める。
n個のコインを同時に投げることを考え,その標準化平均を計算する。標準化平均を計算するための関数を作成する。
コイントスのシミュレーションをおこない,そのヒストグラムをプロットする。
コイントスのヒストグラムと標準正規分布を重ねて表示し,中心極限定理の成立を視覚的に確認する。
コイントス(再考)#
大数の法則を説明する際に説明したコイントスを再考しよう。表を1,裏を0とし,それぞれの確率は\(p=0.5\)とする。以下が成り立つ。
平均:\(p=0.5\)
分散:\(p(1-p)=0.5^2\)
標準偏差:\(\sqrt{p(1-p)}=0.5\)
n=20個のコインを同時に投げる場合,1(表)が発生した回数の平均は次のように計算できることを説明した。
n = 20
toss = [random.randint(0,1) for _ in range(n)]
head = sum(toss)
head / n
0.6
ここまでのコードを利用して,上の式(3)に従って,この平均を標準化した値を計算してみよう
(head/n - 0.5) / ( 0.5/np.sqrt(n) )
0.8944271909999157
このような値を数多く計算して中心極限定理を考えていくことになる。
関数化#
上では一回だけのシミュレーションをおこなった。以下では任意の回数のシミュレーションをおこなうために,上のコードを関数にまとめることにする。
def standardized_mean(n):
"""
引数:
n:同時にトスするコインの数
戻り値:
コインの表の平均を標準化した値"""
toss = [random.randint(0,1) for _ in range(n)]
head = sum(toss)
st_mean = (head/n - 0.5) / ( 0.5/np.sqrt(n) )
return st_mean
この関数はnが与えられれば,標準化された平均を返す。n=20で実行しよう。
standardized_mean(20)
1.341640786499874
この値は20個のコインを同時に投げた結果の平均を標準化した値である。standardized_mean()関数を実行するたびに,コインが投げられ標本が集められるので,標準化平均の値は上の結果とは異なる。実行するたびに異なる値を取るランダム変数を返すことになる。
次に,2個の同時コイントスを20回おこない,毎回標準化平均を計算するとしよう。このシミュレーションの結果は次の内包表記で生成することができる。
[standardized_mean(2) for _ in range(20)]
[0.0,
0.0,
1.4142135623730951,
0.0,
1.4142135623730951,
-1.4142135623730951,
0.0,
1.4142135623730951,
1.4142135623730951,
1.4142135623730951,
0.0,
0.0,
0.0,
-1.4142135623730951,
1.4142135623730951,
1.4142135623730951,
1.4142135623730951,
1.4142135623730951,
1.4142135623730951,
0.0]
ランダム変数なので,実行する度に異なる値が並ぶ。また同じ値が複数回発生していることも確認できるだろう。
ヒストグラム#
前準備#
上の例では次のシミュレーションを行ったが,もう一度考えてみよう。
同時に投げるコインの数(標本の大きさ):
n=2シミュレーションの回数(
n枚の同時コイントスの回数):N=10(N組の標本)
この場合,n=1のコインを投げる度に,次の4つの組み合わせの内の1つが実現し,標準化された平均が計算されている。
{裏,裏}:-1.414..{表,裏}:0{裏,表}:0{表,表}:1.414..
-1.414..,0,1.414..の3つの値しか発生していない事がわかる。更に,シミュレーションの回数Nが100であっても,1_000_000であっても,投げるコインの数はn=2なので,3つの値しか発生しないことは自明である。
もちろん,このままplt.hist(toss)としてヒストグラムを表示することもできる。しかし,その場合,引数bins=10がデフォルトとして使われ,階級の数(棒の数)が10となる。-1.414..,0,-1.414..の3つの値しかないため,10の階級の内,7つは頻度が0となるため視覚的に見辛いヒストグラムとなる。一方で,引数bins=3を設定すると,3つの階級のみが表示されるため,視覚的に認識し易いヒストグラムとなる。ここで問題は,コインの数n=2であれば,階級の数は3とわかるが,nが任意の数(例えば,n=64)をとる場合,どのようにして階級の数を設定すれば良いだろうか。
階級の数はtossの重複しない値の数と等しい,ということを思い出そう。要するに,tossから重複しない値を取り出し,その数を階級の数に使えば良い。重複する値だけを抽出するにはset()関数が便利である。tossを引数にしてset()関数を使ってみよう。
set(toss)
{0, 1}
3つの値だけが抽出されており,波括弧{}で挟まれている。これは辞書ではなく,「集合」と呼ばれるコンテナデータ型である(集合の説明は割愛)。要素の数を数えるには,リストやタプルと同じようにlen()を使えば良い。
unique = len( set(toss) )
unique
2
ヒストグラムのプロット#
では実際にヒストグラムをプロットしてみよう。例として次の数値を使う。
同時に投げるコインの数(標本の大きさ):
n=1シミュレーションの回数(
n枚の同時コイントスの回数):N=30
この場合,n=1のコインを投げる度に,次の2つの組み合わせの内の1つが実現し,標準化された平均が計算されることになる。
{裏}:-1.0{表}:1.0
# パラメータの設定
n = 1
N = 10
# コイントスのシミュレーション
toss = [standardized_mean(n) for _ in range(N)] #1
# 標準化平均の重複しない値の数
unique = len( set(toss) ) #2
print(f'標準化平均の重複しない値の数(x軸):{unique}') #3
# ヒストグラム
plt.hist(toss,
bins=unique,
ec='white',
density=True)
plt.title(f'Coins: n={n},\nRepetition: N={N}',
size=23) #4
plt.xlabel('Standardized Mean', size=15) #5
pass
標準化平均の重複しない値の数(x軸):2
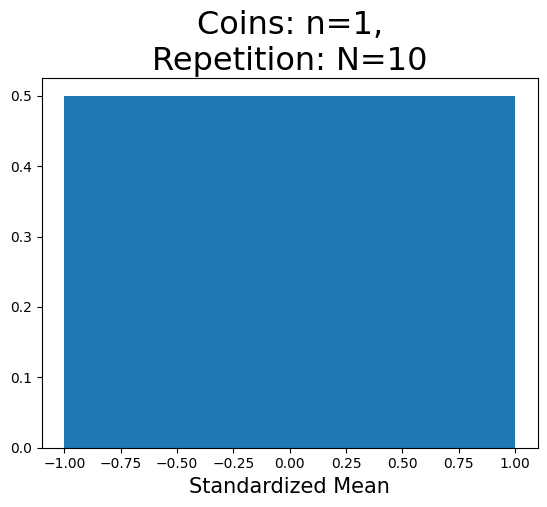
<コードの説明>
#1:n枚の同時コイントスをN回繰り返し,標準化平均を計算したリストを変数tossに割り当てる。#2:set()関数は引数の唯一の値を返すが,set(toss)は標準化平均の唯一の値を返す。更に,len(set(toss))はその数を返しており,その値を変数uniqueに割り当てている。#3:uniqueの値を表示する。#4:タイトルを設定する。#5:横軸のラベルを設定する。
<注意点>
ヒストグラムの柱の幅は階級区間を示すが,シミュレーションの値がそれぞれの区間内で散らばっているのではない。左の柱にある値は
-1.0のみであり,右の柱にある値は1.0のみである。その2つの数が「標準化平均の唯一の値の数」である。
Note
棒グラフとして表示したい場合はplt.bar()を使うことができる。
n = 1
N = 10
toss = [standardized_mean(n) for _ in range(N)]
unique = sorted(list(set(toss)))
count_on_y_axis = [toss.count(i) for i in unique]
xlabel = [str(i) for i in unique]
plt.bar(xlabel, count_on_y_axis)
plt.title(f'Coins: n={n}, Repetition: N={N}', size=23)
plt.xlabel('Standardized Mean', size=15)
plt.show()
プロットの関数化#
ヒストグラムを描くことができたが,nとNが異なる値を取る度に上のコードをコピペして使うの面倒なので,関数としてまとめよう。
def plot_hist(n, N=10_000): #1
# コイントスのシミュレーション
toss = [standardized_mean(n) for _ in range(N)]
# 標準化平均の重複しない値の数
unique = len(set(toss))
print(f'標準化平均の重複しない値の数(x軸):{unique}')
# ヒストグラム
plt.hist(toss,
bins=unique,
ec='white',
density=True)
plt.title(f'Coins: n={n},\n Repetition: N={N}',
size=23)
plt.xlabel('Standardized Mean', size=15)
plt.show() #2
この関数の中身は上のコードと同じとなる。違いは次の2点だけである。
#1:関数名をplot_histとして,引数はnとN。ただし,Nのデフォルトの値を10_000#2:plt.show()とは,文字通りこの行の「上で作成された図を表示する」ことを意味している。この場合,この行がないと,一つ前の図の上にプロットされることになる。
シミュレーション#
これでシミュレーションの準備は整った。n(とN)の数値を変えてプロットしてみよう。
n=1の場合#
plot_hist(1, 5)
plot_hist(1)
標準化平均の重複しない値の数(x軸):2
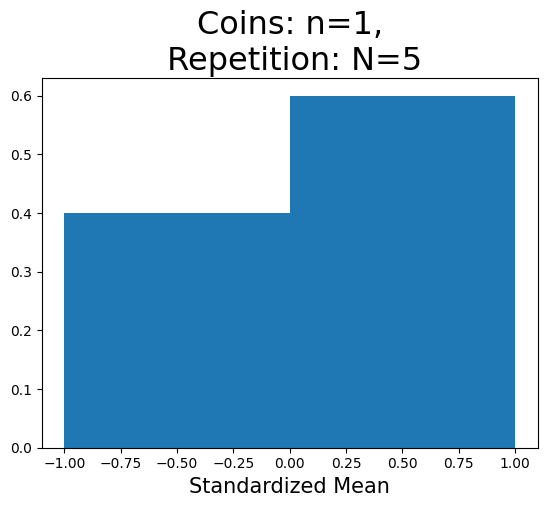
標準化平均の重複しない値の数(x軸):2
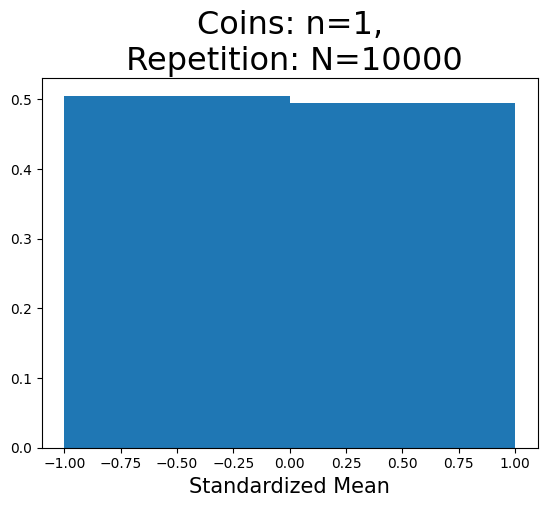
Nが小さい(10)とランダムな影響が強く現れるが,大きくなると(10000)大数の法則によって-1と1の割合は0.5に近づいている。一方で,Nが大きくなっても,分布は標準正規分布とは大きく異なっている。
n=2の場合#
plot_hist(2,10)
plot_hist(2)
標準化平均の重複しない値の数(x軸):3
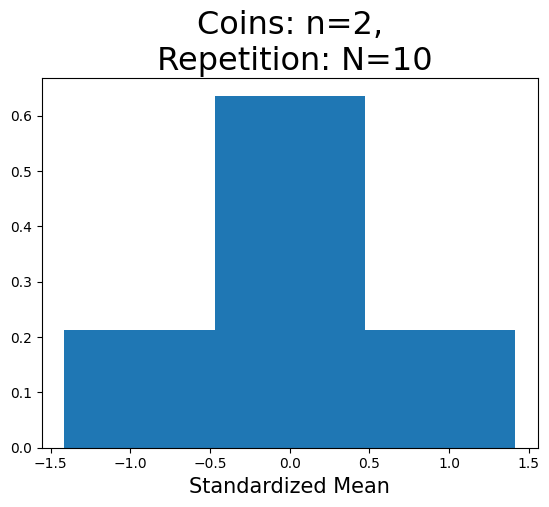
標準化平均の重複しない値の数(x軸):3
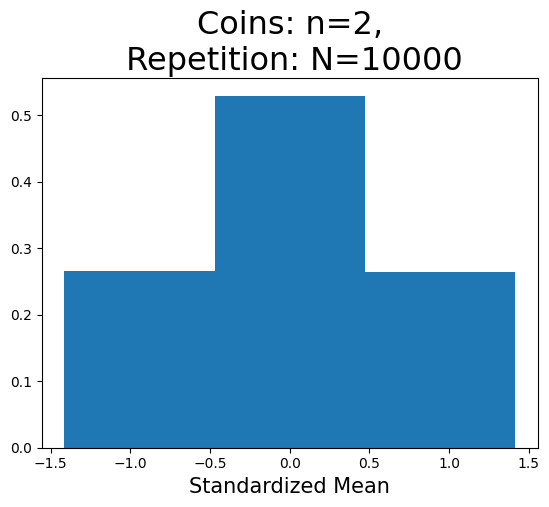
Nが大きくなると,大数の法則によって左右対称の分布となっている。しかし,依然として標準正規分布とは異なっている。
n=12の場合#
plot_hist(12,24)
plot_hist(12)
標準化平均の重複しない値の数(x軸):8
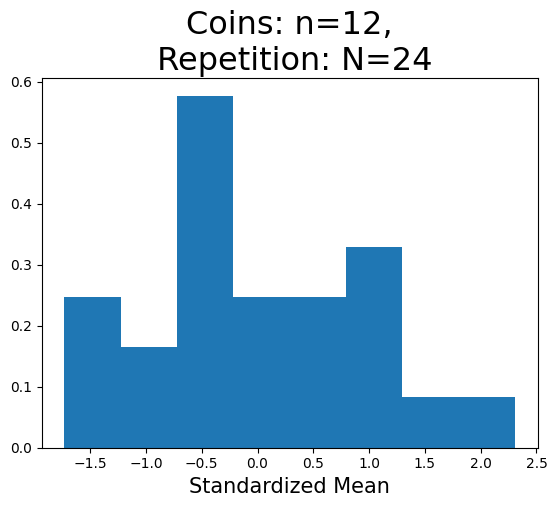
標準化平均の重複しない値の数(x軸):13
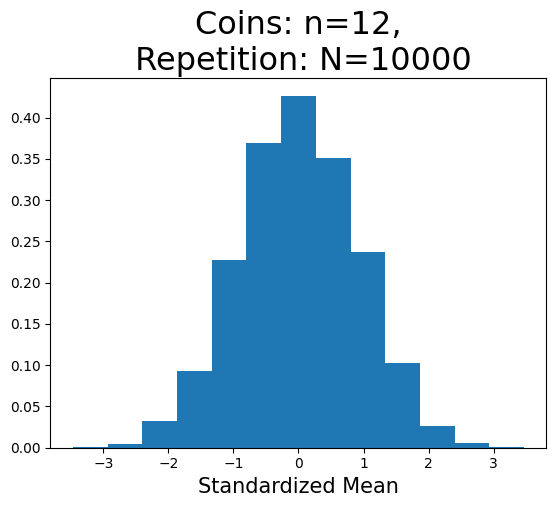
Nが小さいとランダムな要素が際立ち明確ではないが,n増加すると標準正規分布に近づいていることが分かる。
n=64の場合#
plot_hist(64,100)
plot_hist(64)
標準化平均の重複しない値の数(x軸):17
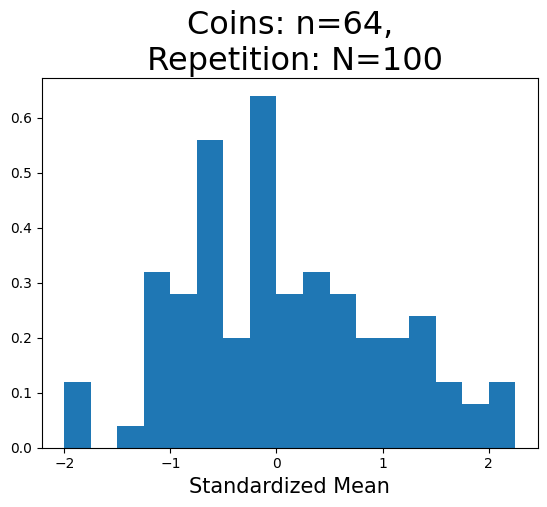
標準化平均の重複しない値の数(x軸):29
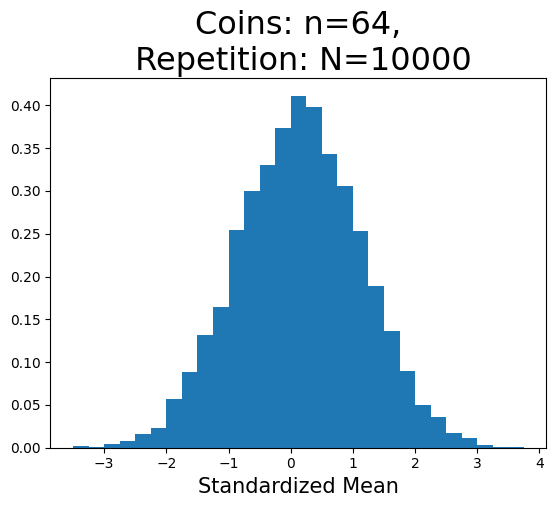
標準正規分布に大きく近づいたことが確認できる。
n=1000の場合#
更にnが増加すると,分布は標準正規分布に収束していくことになる。次のコードはn=1000とN=10_000の下でのヒストグラムと標準正規分布を重ねてプロットしている。標準正規分布の近似としては十分な重なり具合と言っていいだろう。
Show code cell source
def plot_hist_normal(n, N=10_000):
# 標準正規分布 ------------------------------------
from scipy.stats import norm
x = xvalues(-4,4,100)
plt.plot(x, norm.pdf(x,0,1))
# コイントスのシミュレーション -------------------------
toss = [standardized_mean(n) for _ in range(N)]
unique = len( set(toss) )
print(f'標準化平均の重複しない値の数(x軸):{unique}')
plt.hist(toss,
bins=sorted( set(toss) ),
ec='white', density=True)
plt.title(f'Coins: n={n},\n Repetition: N={N}',size=23)
plt.xlabel('Standardized Mean', size=15)
plt.xlim([-4,4])
plt.show()
plot_hist_normal(1000)
標準化平均の重複しない値の数(x軸):111
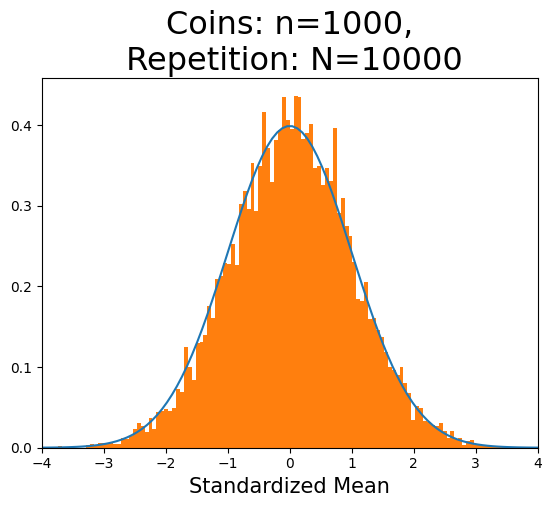
Hint
このプロットのオレンジ色はヒストグラムだが,そのコードの階級に関する引数は次のように設定してある。
bins=sorted( set(toss) )
これは,上で説明した引数bins=len(set(toss))と異なる。もちろん,len(set(toss))を使っても良いが,その場合,nが大きいと青色の標準正規分布の線から大きくはみでる階級が発生する。それを調整するためにsorted(set(toss))を使っている。sorted()は,tossに含まれる値を昇順に並び替える関数である。昇順に並び替えたtossをbinsに使うことにより,それらの値を階級の境界に使うことになる。例えば,n=3を考えてみよう。上で説明したが,標準化された平均の値は-1.414..,0,1.141..の3つとなる。bins=sorted(set(toss))を設定することにより,1つ目の階級は[-1.414,0),2つ目の階級は[0,1.414]となる。この例から分かるように,標準化された平均の値は3つあるが,階級の数は2つとなる。