Pandas:図示#
説明#
import numpy as np
import pandas as pd
import japanize_matplotlib
# 警告メッセージを非表示
import warnings
warnings.filterwarnings("ignore")
プロット用のパッケージMatplotlibを紹介したが,実はPandasのDataFrameとSeriesにはメソッドplot()が備えられており,それを使えば基本的なプロットをより簡単なコードで実現できる。裏で動いているのはMatplotlibであり,より複雑な図を作成する場合は、Matplotlibのコードを直接書くことが必要になるだろうが,手っ取り早くプロットしたい場合には重宝する手法である。詳細は参考サイト(英語)を参考にして欲しいが,ここでは基本的な使い方を紹介する。
次のdfを使って説明する。
dic = {'X':[10, 20, 30],
'Y':[5.0, 30.0, 15.0],
'Z':[3.0, 2.0, 5.0]}
df = pd.DataFrame(dic)
df
| X | Y | Z | |
|---|---|---|---|
| 0 | 10 | 5.0 | 3.0 |
| 1 | 20 | 30.0 | 2.0 |
| 2 | 30 | 15.0 | 5.0 |
プロット方法#
DataFrame#
プロット方法は簡単で,次の基本構文となる。
df.plot(x="列ラベル", y="列ラベル")
x:横軸に使う列ラベル(文字列)y:縦軸に使う列ラベル(文字列、複数の場合はリスト)
df.plot(x='X', y='Y')
<Axes: xlabel='X'>
凡例は自動的に表示され,列ラベルが使われる。次の引数を追加すると凡例は非表示になる。
legend=False
図の上に文字が表示されるが,表示したくない場合は最後に
;を加えるか次の行にpassと書くと良いだろう。
縦軸に複数の変数を表示したい場合は,次のようにリストとして指定する。
df.plot(x="列ラベル", y=["列ラベル1", "列ラベル2"])
df.plot(x='X', y=['Y', 'Z'])
<Axes: xlabel='X'>
上の例では引数xとyを指定したが,xを指定しない場合はどうなるか試してみよう。
df.plot(y='Y')
pass
縦軸はYだが,横軸には行インデックスが使われることになる。この場合,行インデックスがfloatとして表示されている。
では、引数なしで実行するとどうなるだろう。
df.plot()
pass
縦軸には全ての列が使われ、横軸には行インデックスが使われている。
Series#
次に,Seriesを考えてみよう。まず,2つのSeriesを作成しよう。
sy = df['Y']
sy
0 5.0
1 30.0
2 15.0
Name: Y, dtype: float64
sz = df['Z']
sz
0 3.0
1 2.0
2 5.0
Name: Z, dtype: float64
両方ともdfの行インデックスが引き継がれている。
Seriesにもメソッド.plot()が実装されているが次の点を覚えておこう。
列が1つしかないため,引数
xとyを指定する必要はない。
syをプロットしてみよう。
sy.plot()
pass
横軸には行インデックスがfloatとして使われており,Seriesの場合,凡例は自動的には表示されない。
次の引数を使うと凡例を表示することができる。
legend=True
更に,次の点でDataFrameを使う場合と異なる。syとszを続けて書いて実行してみよう。
sy.plot(legend=True)
sz.plot(legend=True)
pass
Seriesの場合,連続してコードを書くと一つの図に表示することができる。この特徴は,次に説明する「飾り付け」を各データ毎別々に設定する際に便利な機能と感じる人もいるだろう。
引数とメソッド#
基本的な引数#
plot()には様々な引数があり図に「飾り付け」をすることができる。詳しくはこのリンクを参照することにして,ここでは基本的な引数だけを紹介する。
style:線のスタイル(複数ある場合はリストにして列の順番で指定する;-,--,-.,:)linewidthorlw:線の幅color:色(リストにして列の順番で指定する; 参照サイト)rは赤kは黒gはグリーン
marker:観測値のマーカー(o,.,>,^などがある; 参照サイト)markersize:マーカーの大きさfontsize:横軸・縦軸の数字のフォントサイズの設定figsize:図の大きさfigsize=(キャンバスの横幅、キャンバスの縦の長さ)
legend:凡例の表示を指定DataFrameの場合はデフォルトはTrueSeriesの場合はデフォルトはFalse複数の図を表示する際は下で説明する「軸」のメソッドとして指定することもできる。
label:凡例の表現を指定grid:グリッド表示(ブール型;デフォルトはFalse)複数の図を表示する際は,この引数は使わずに下で説明する「軸」のメソッドとして指定する。
ax:プロットする「軸」を指定する。1つの「軸」に複数の図を表示する際に使う(後で使い方を説明する)。
df.plot( # 引数 x, y は省略
style=[':','--','-'],
linewidth=2,
color=['r','k','g'],
marker='o',
markersize=10,
fontsize=15,
figsize=(8, 4), # 8は横軸、4は縦軸のサイズ
legend=False,
grid=True,
)
pass
タイトルとラベルのサイズの調整#
タイトルのフォント・サイズの指定,横軸と縦軸のラベルとフォント・サイズの指定をおこなう場合は、plot()の引数ではなく下で説明する方法でおこなう。この方法を理解するために、Pandas(実はMatplotlib)が表示する図はFig. 2で示している階層的な構造となることをイメージして欲しい。ここで重要なのは「キャンバス」と「軸」の違いである。
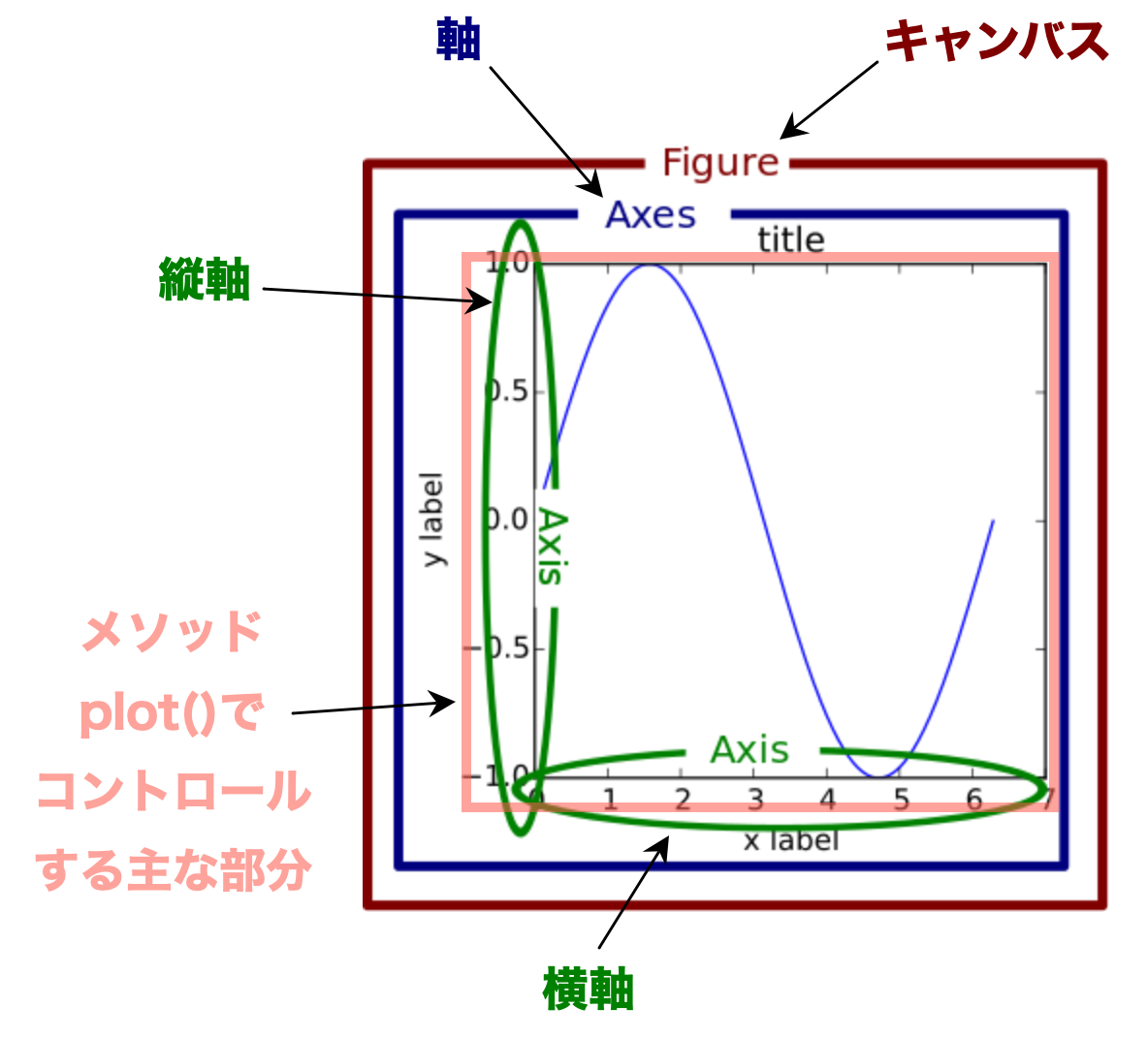
Fig. 2 「キャンバス」と「軸」の関係#
「キャンバス」とは実際に表示される領域であり,実際には表示されない「透明のキャンバス」である。
figureやfigなどの変数名や引数名があれば、「キャンバス」を指していると理解すれば良いだろう。
「軸」とは1つの図を表示する「キャンバス」上の区域である。
axやaxesなどの変数名があれば、「軸」を表していると理解すれば良いだろう。「キャンバス」上に複数の図を表示する場合は複数の「軸」が必要となる。
「軸」に図のタイトルや縦軸・横軸のラベルなどを追加することになる。
「軸」の中にメソッド.plot()を使いグラフを表示することになる。
従って,概ね次のように理解して良いだろう。
上で説明した「基本的な引数」は上の図のピンクのエリア内での変更となる。
figsizeは「キャンバス」の大きさを指定する引数だが,メソッドplot()は自動で「キャンバス」を作成するためplot()内で変更できるようになっている。
タイトルや縦・横軸ラベルは「軸」のメソッドを使い変更する。
では実際に手順を説明する。
df.plot()は自動で「キャンバス」と「軸」を作成すると同時に「軸」を返す。それを変数(例えば,ax)に割り当てる。axのメソッドを使って以下を設定する。タイトル:
.set_title()横軸ラベル:
.set_xlabel()縦軸ラベル:
.set_ylabel()
実際にそれらの引数を使ってプロットしてみよう。
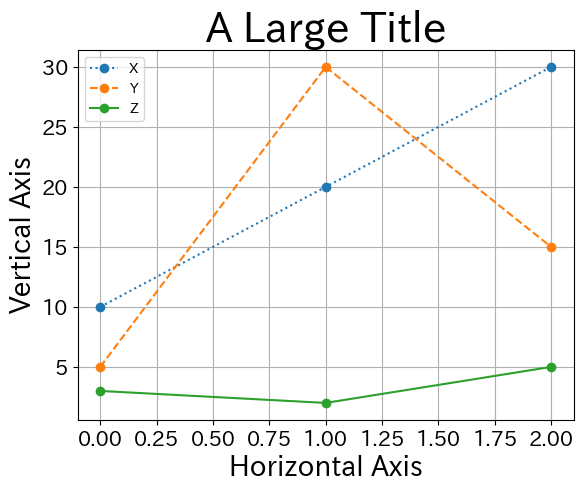
ax = df.plot( # 引数 x, y は省略
grid=True,
style=[':','--','-'],
marker='o',
fontsize=15,
)
ax.set_title('A Large Title', size= 30) # タイトルの設定
ax.set_xlabel('Horizontal Axis', size=20) # 横軸ラベルの設定
ax.set_ylabel('Vertical Axis', size=20) # 縦軸ラベルの設定
pass
「軸」を指定してプロットする場合#
上で「軸」のメソッドとしてタイトルなどを追加できることを説明したが,plot()の引数として「軸」を指定して図を追加することができる。次のコードを考えてみよう。
ax_ = df.plot(x='X', y='Y') #1
df.plot(x='X', y='Z', ax=ax_) #2
pass
#1の右辺では「キャンバス」と「軸」が自動生成され,その内「軸」のみが返され変数ax_に割り当てられている。#2のplot()の引数axは「軸」を指定する引数であり,それにax_を設定している。即ち,Zを「軸」ax_にプロットすることを指定している。このコードには2つの利点がある。XとYと異なる「飾り付け」をZに簡単に施すことができる。2行目に
df0ではなく別のDataFrameを使うことも可能となる。
もちろん,タイトルや軸ラベルのメソッドをつけ加えることも可能である。
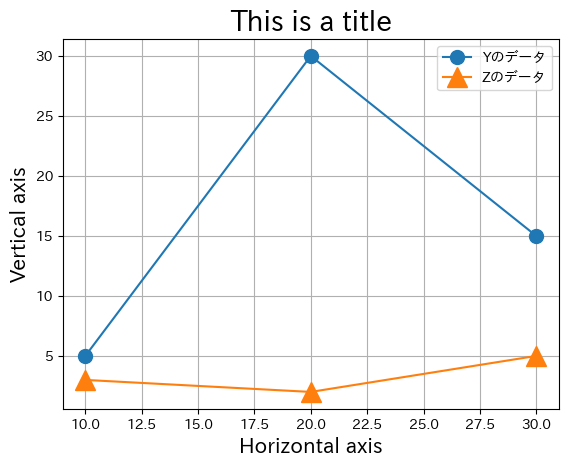
ax_ = df.plot(x='X', y='Y',
marker='o', markersize=10, label='Yのデータ')
df.plot(x='X', y='Z', ax=ax_,
marker='^', markersize=15, label='Zのデータ')
ax_.set_title('This is a title', size=20)
ax_.set_xlabel('Horizontal axis', size=15)
ax_.set_ylabel('Vertical axis', size=15)
ax_.grid()
pass
また上のコードの最後に次の行を付け加えている。
ax_.grid():グリッド線を表示するメソッド。1つの「軸」に
plotを複数回適用する場合,個々のplotの引数grid=Trueを使わずにax_.grid()を指定すると分かりやすいですコードになる。
図を並べる#
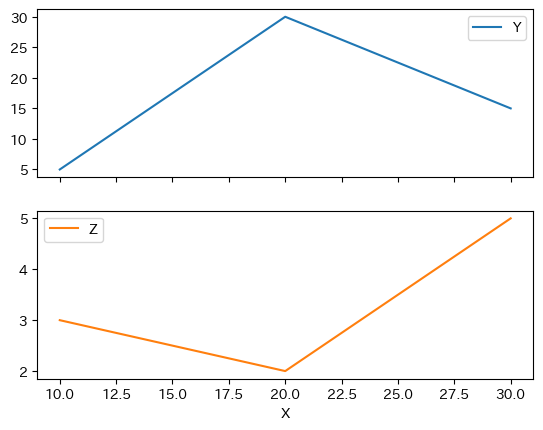
図を縦に並べるにはsubplots=Trueを指定する。
df.plot(x='X', subplots=True)
pass
図を横に並べるにはlayout=(1,2)を付け加える。layoutは図の配置を行列のように考えて指定し、1は行の数であり、2は列の数。
layout(行の数、列の数)
df.plot(x='X', subplots=True, layout=(1,2), figsize=(8,3))
pass
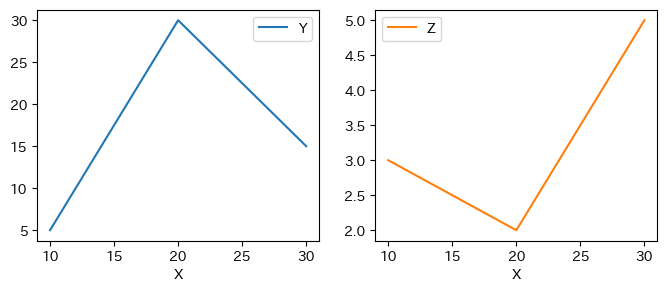
図を並べる際も引数xを省略すると,横軸には行インデックスが使われることになる。
2軸グラフ#
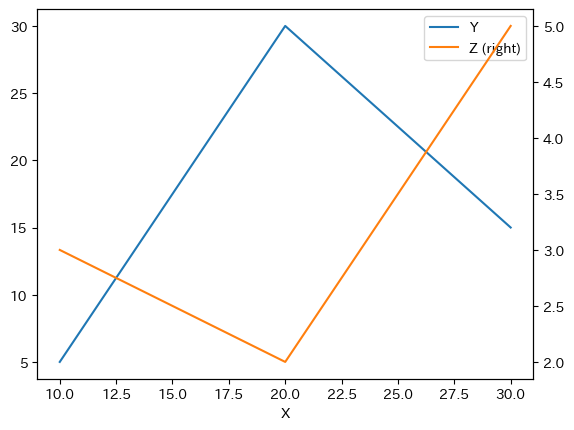
左縦軸をYに,右縦軸をZに使うとしよう。その場合,引数secondary_yにZを設定する。
df.plot(x='X', secondary_y='Z')
pass
別々の飾り付けをする場合は次のようにすると良いだろう。
ax_ = df.plot(x='X', y='Y')
df.plot(x='X', y='Z',
ax=ax_, #1
secondary_y=True, #2
marker='^', #3
markersize=10, #4
linestyle=':', #5
)
pass
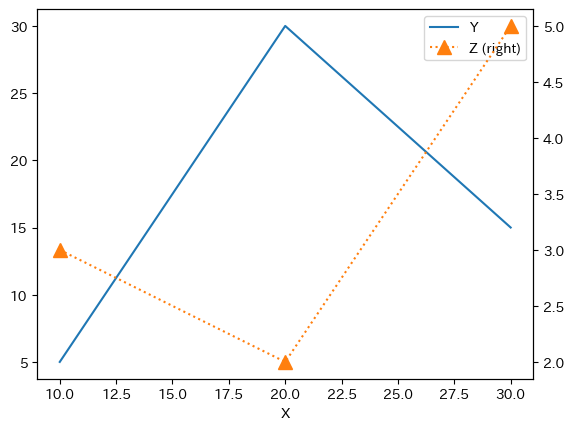
上のコードとの主な違い:
#1:ax=ax_:「軸」ax_にZをプロットする。#2:secondary_y=True:Zを右軸に使うことを指定する。#3〜#5:Zの飾り付け
日本語#
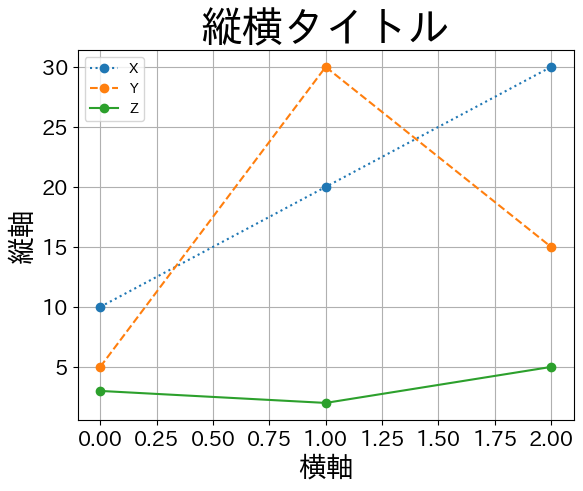
2つ方法を紹介するが、japanize_matplotlibを使う方法がより簡単であろう。
japanize_matplotlib#
使い方は到って簡単で、Pandasと同様にインポートするだけである。
import japanize_matplotlib
ax = df.plot( # 引数 x, y は省略
grid=True,
style=[':','--','-'],
marker='o',
fontsize=15,
)
ax.set_title('縦横タイトル', size= 30)
ax.set_xlabel('横軸', size=20)
ax.set_ylabel('縦軸', size=20)
pass
フォントを指定する#
2つの方法:
フォントはインストールせず、PC内にあるフォントを指定する。
フォントをインストールする方法
方法1の場合、以下で説明に使う変数jfontにフォントを指定する。
* Macの場合、例えばAppleGothic
* Windowsの場合、例えばYu Gothic
* この方法では一部の日本語が文字化けする場合がある。
方法2の場合:
このサイトから次の内の1つをダウンロードする。
このサイトに従ってインストールする。
次の両方もしくは1つがPCにインストールされる
IPAexMincho(IPAex明朝)
IPAexGothic(IPAexゴシック)
上の例を使い、設定方法の例を示す。
jfont = 'IPAexGothic' #1
ax = df.plot( # 引数 x, y は省略
grid=True,
style=[':','--','-'],
marker='o',
fontsize=15,
)
ax.set_title('縦横タイトル', size= 30, fontname=jfont) #2
ax.set_xlabel('横軸', size=20, fontname=jfont) #3
ax.set_ylabel('縦軸', size=20, fontname=jfont) #4
ax.legend(prop={'family':jfont, 'size':17}) #5
pass
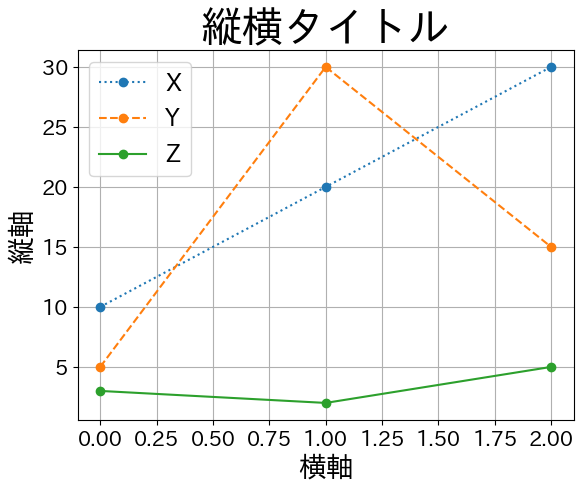
#1: 使用するフォントをjfontに割り当てる。#2: 引数fontnameでjfontを指定する。タイトルのフォントが変更される。#3: 引数fontnameでjfontを指定する。横軸名のフォントが変更される。#4: 引数fontnameでjfontを指定する。縦軸名のフォントが変更される。#5:legendは他と設定方法が異なる。propはフォントのプロパティを設定する引数であり、辞書で指定する。キー
familyに値jfontを指定する。凡例のフォントが変更される。キー
sizeに数値を設定してフォントの大きさが変更される。
この例では個別にフォントを設定したが、一括で全てのフォントを変更する方法もあるが説明は割愛する。
マクロ経済学の例#
投資関数#
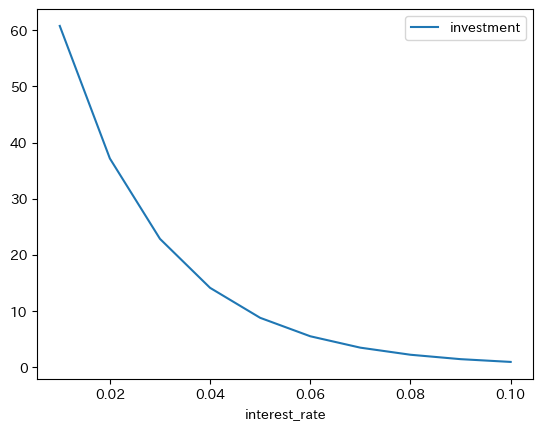
実質利子率rによって投資がどのように変化するかを考えてみよう。まず投資関数を次のように仮定する。
def investment(r):
return 100/(1+r)**50
100:実質利子率が0の場合の投資
実質利子率は次のarrayで与えられるとする。
r_arr = np.arange(0.01,0.11,0.01)
r_arr
array([0.01, 0.02, 0.03, 0.04, 0.05, 0.06, 0.07, 0.08, 0.09, 0.1 ])
次に関数investmentとr_arrを使い投資のarrayを作成しよう。
inv_arr = investment(r_arr)
inv_arr
array([60.80388247, 37.15278821, 22.81070798, 14.07126153, 8.7203727 ,
5.42883618, 3.39477594, 2.13212286, 1.34485389, 0.85185513])
これらのデータを使いDataFrameを作成する。
df_inv = pd.DataFrame({'investment':inv_arr,
'interest_rate':r_arr})
最初の5行を表示する。
df_inv.head()
| investment | interest_rate | |
|---|---|---|
| 0 | 60.803882 | 0.01 |
| 1 | 37.152788 | 0.02 |
| 2 | 22.810708 | 0.03 |
| 3 | 14.071262 | 0.04 |
| 4 | 8.720373 | 0.05 |
ではプロットしてみよう。
df_inv.plot(x='interest_rate', y='investment')
pass
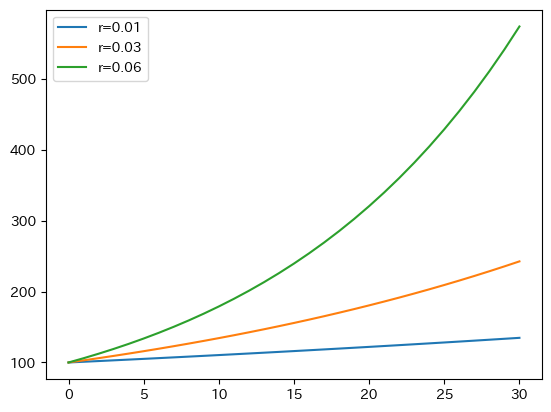
将来価値#
x万円を実質年率r%の利息を得る金融商品に投資し,t年間の将来価値(期首の値)をリストで示す関数は以下で与えられた。
def calculate_futre_value(x, r, t):
value_list = [x] # 初期値が入ったリスト
for year in range(1,t+1): # 1からtまでの期間
x = x*(1+r) # 来期のxの値の計算
value_list.append(x) # リストに追加
return value_list # リストを返す
これを使い,
x=100t=30
の下で実質利子率が次のリストで与えられる値を取る場合の将来価値を図示する。
r_list = [0.01, 0.03, 0.06] # 実質利子率のリスト
dic = {} # 空の辞書
for r in r_list:
dic['r='+str(r)] = calculate_futre_value(100, r, 30) # 辞書に追加
df_future = pd.DataFrame(dic) # DataFrameの作成
dic['r='+str(r)]の説明:
str(r):r_listの要素のダミーであるrは浮動小数点型なので関数str()を使って文字列型に変換する。'r='+str(r):文字列型のr=と文字列型のstr(r)を+で結合する。dic['r='+str(r)]:辞書dicにキー・値のペアを作成する。キー:
'r='+str(r)値:
calculate_futre_value(100, r, 30)の返り値
最初の5行を表示する。
df_future.head()
| r=0.01 | r=0.03 | r=0.06 | |
|---|---|---|---|
| 0 | 100.000000 | 100.000000 | 100.000000 |
| 1 | 101.000000 | 103.000000 | 106.000000 |
| 2 | 102.010000 | 106.090000 | 112.360000 |
| 3 | 103.030100 | 109.272700 | 119.101600 |
| 4 | 104.060401 | 112.550881 | 126.247696 |
最後の5行を表示する。
df_future.tail()
| r=0.01 | r=0.03 | r=0.06 | |
|---|---|---|---|
| 26 | 129.525631 | 215.659127 | 454.938296 |
| 27 | 130.820888 | 222.128901 | 482.234594 |
| 28 | 132.129097 | 228.792768 | 511.168670 |
| 29 | 133.450388 | 235.656551 | 541.838790 |
| 30 | 134.784892 | 242.726247 | 574.349117 |
df_future.plot()
pass
その他のプロット#
種類#
2つの書き方が準備されている。
書き方1:
.plot.xxxx()
ここで
xxxxは、プロットの種類を表す。書き方2:
.plot.(kind='xxxx')
ここで
kindはプロットの種類を指定する引数であり,'xxxx'は文字列。
この2つの方法は同じプロットを表示することなる。
まず,各プロットについての箇条書きでまとめた後,実際にデータを使いプロットについて説明することにする。
ライン・プロット
上で説明した直線・曲線のプロット。
書き方1:
.plot.line()書き方2:
.plot()であり,引数kind='line'ははデフォルトの値。
散布図(
DataFrameのみ)書き方1:
.plot.scatter()書き方2:
.plot(kind='scatter')
ヒストグラム(連続変数に使う)
書き方1:
.plot.hist()書き方2:
.plot(kind='hist')histはHISTogramのHIST
カーネル密度推定プロット
書き方1:
.plot.kde()もしくは.plot.density()書き方2:
.plot(kind='kde')もしくは.plot(kind='density')kdeはKernel Density EstimateのKDE
縦向きの棒グラフ(カテゴリーなどの離散変数に使う)
書き方1:
.plot.bar()書き方2:
.plot(kind='bar')
横向き棒グラフ(カテゴリーなどの離散変数に使う)
書き方1:
.plot.barh()書き方2:
.plot(kind='barh')barhのhはHorizontalのH
ボックスプロット
書き方1:
.plot.box()書き方2:
.plot(kind='box')
エリア・プロット
書き方1:
.plot.area()書き方2:
.plot(kind='area')
パイチャート
書き方1:
.plot.pie()書き方2:
.plot(kind='pie')
六角形プロット(
DataFrameのみ)書き方1:
.plot.hexbin()書き方2:
.plot(kind='hexbin')
上で説明したライン・プロットの引数は他のプロットと共通のものが多いが,それぞれ独自の引数もある。
以下では散布図,ヒストグラム,カーネル密度推定プロット,棒グラフについて説明する。 加えて,縦線と横線を表示する方法も紹介する。
説明には次のコードで生成するDataFrameを使う。列XとYには標準正規分布(平均0,標準偏差1)から生成した100個のランダム変数が含まれている。Zには正規分布(平均2,標準偏差1)から抽出した100個のランダム変数が格納されている。
rng = np.random.default_rng()
df1 = pd.DataFrame({'X':rng.normal(size=100),
'Y':rng.normal(size=100),
'Z':rng.normal(loc=2, size=100)})
X,Yは同じ標準正規分布から生成されているが,異なる値から構成されている。
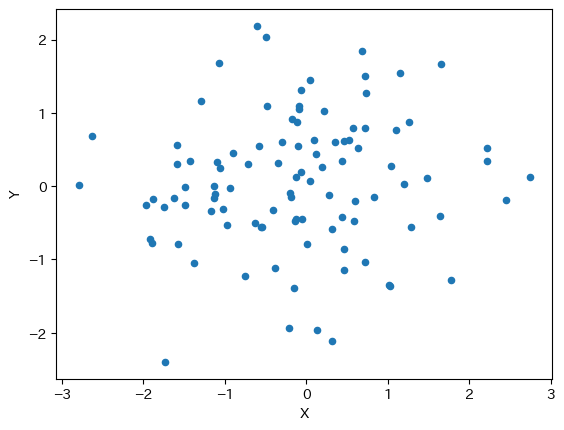
散布図#
散布図をプロットする場合は次の構文となる。
<書き方1>
df1.plot.scatter(x='列ラベル', y='列ラベル')
<書き方2>
df1.plot(x='列ラベル', y='列ラベル', kind='scatter')
x:横軸に使う列ラベル(文字列)y:縦軸に使う列ラベル(文字列)
列XとYを使ってプロットしてみよう。
df1.plot.scatter(x='X', y='Y')
pass
<基本的な引数>
様々な引数があり図に「飾り付け」をすることができる。詳しくはこのリンクを参照することにして,ここでは基本的な引数だけを紹介する。
title:図のタイトル(文字列型で指定)color:色(リストにして列の順番で指定する; 参照サイト)rは赤kは黒gはグリーン
marker:観測値のマーカー(o,.,>,^などがある; 参照サイト)s:マーカーの大きさ(markersizeではない!)fontsize:横軸・縦軸の数字のフォントサイズの設定figsize:図の大きさfigsize=(キャンバスの横幅、キャンバスの縦の長さ)
legend:凡例の表示を指定DataFrameの場合はデフォルトはTrueSeriesの場合はデフォルトはFalse
label:凡例の表現を指定(Seriesのみ有効)grid:グリッド表示(ブール型;デフォルトはFalse)ax:プロットする「軸」を指定する。
df1.plot.scatter(x='X', y='Y',
title='タイトルです',
color='red',
marker='^',
s=100,
fontsize=20,
figsize=(8,4),
# legend=False,
label='Yの判例',
grid=True
)
pass
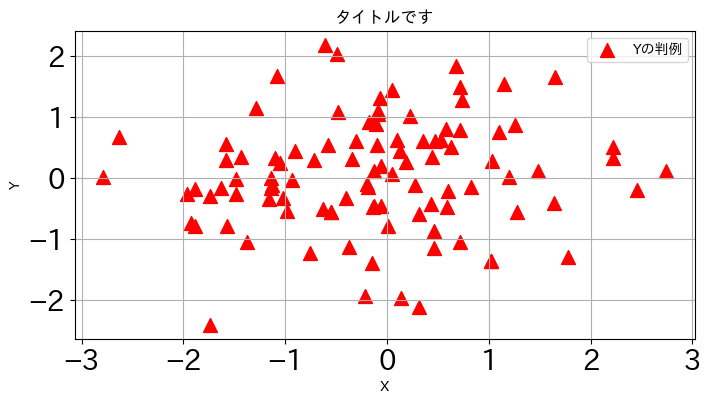
この図ではタイトルと横軸・縦軸ラベルの大きさが調整できていないが,上で説明したタイトルとラベルのサイズの調整のコードと共通なので,そちらを参照しよう。
またライン・プロットと同じように引数axを使うことにより,複数の散布図を重ねてプロットできる。次のコードはXとY,そしてXとZの散布図を同じ「軸」に表示している。
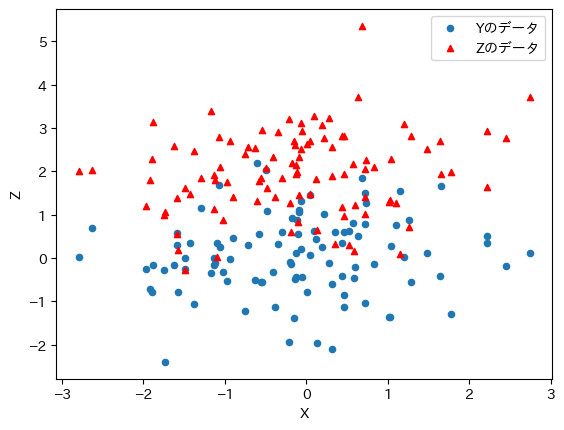
ax_ = df1.plot.scatter(x='X', y='Y', label='Yのデータ')
df1.plot.scatter(x='X', y='Z',
color='red', marker='^', label='Zのデータ', ax=ax_)
pass
ヒストグラム#
ヒストグラムは次の構文となる。
<書き方1>
df1.plot.hist(y='列ラベル')
<書き方2>
df1.plot(y='列ラベル', kind='hist')
y:縦軸に使う列ラベル(文字列、複数指定する場合はリスト)横軸は自動で設定されるため
xは指定する必要はない
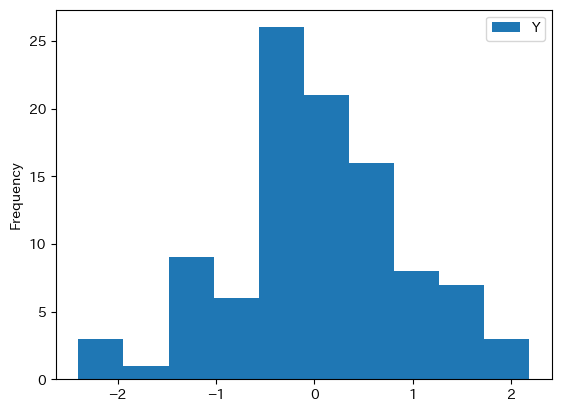
df1.plot.hist(y='Y')
pass
<基本的な引数>
様々な引数があり図に「飾り付け」をすることができる。詳しくはこのリンクを参照することにして,ここでは基本的な引数だけを紹介する。
title:図のタイトル(文字列型で指定)bins:柱の数color:色(リストにして列の順番で指定する; 参照サイト)rは赤kは黒gはグリーン
edgecolor又はec:柱の境界線の色alpha:透明度(0から1.0; デフォルトは1)density:縦軸を相対度数にする(デフォルトはFalse)全ての柱の面積の合計が
1になるように縦軸が調整される。1つの柱の高さが1よりも大きくなる場合もある。
fontsize:横軸・縦軸の数字のフォントサイズの設定figsize:図の大きさfigsize=(キャンバスの横幅、キャンバスの縦の長さ)
legend:凡例の表示を指定DataFrameの場合はデフォルトはTrueSeriesの場合はデフォルトはFalse
label:凡例の表現を指定(Seriesのみ有効)grid:グリッド表示(ブール型;デフォルトはFalse)subplots:複数の図をプロットする(詳細はライン・プロットを参照)ax:プロットする「軸」を指定する。
引数を指定してXのヒストグラムをプロットしてみよう。
df1.plot.hist(y='Y',
bins=20,
title='タイトルです',
color='red',
ec='white',
alpha=0.5,
density=True,
fontsize=20,
figsize=(8,4),
legend=True,
label='Xの凡例',
grid=True
)
pass
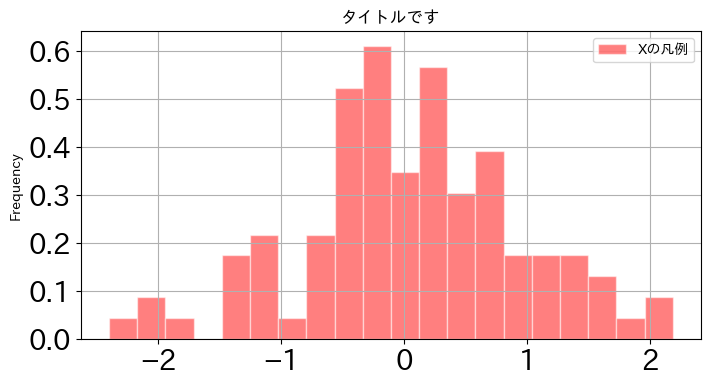
この図ではタイトルと横軸・縦軸ラベルの大きさが調整できていないが,上で説明したタイトルとラベルのサイズの調整のコードと共通なのでそちらを参照しよう。
次に複数のデータを重ねてプロットする場合を考えよう。ここで役に立つ引数がalphaである。
df1.plot.hist(y=['Y','Z'],
bins=30,
color=['r','k'],
edgecolor='k',
alpha=0.4)
pass
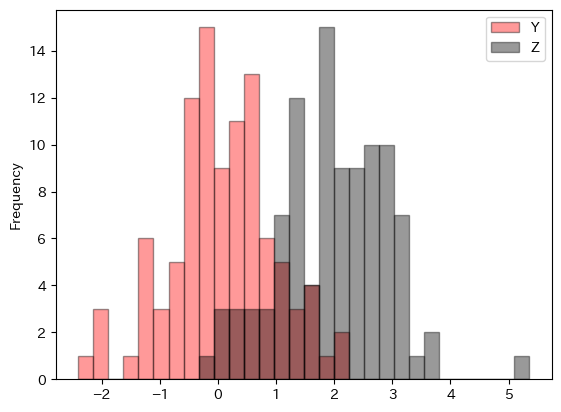
濃い部分が重なっている部分となる。また柱を積み上げて表示するにはstacked=True(デフォルトはFalse)を使う。
df1.plot.hist(y=['Y','Z'],
bins=30,
color=['r','k'],
edgecolor='white',
stacked=True)
pass
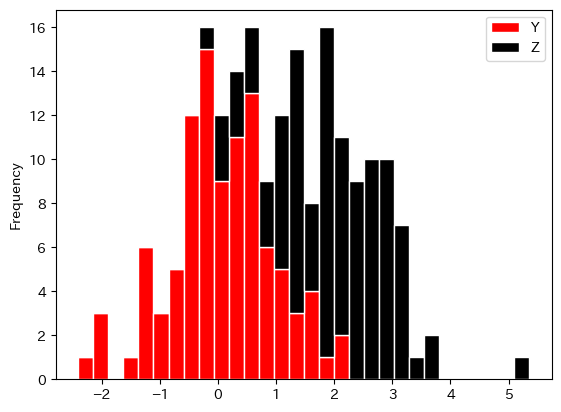
赤の上に黒が積み上げられている。
カーネル密度推定プロット#
ヒストグラムは縦軸に度数,横軸に階級を取ったグラフだが,関連する手法にカーネル密度推定と呼ばれるものがある。考え方は簡単で,上のようなヒストグラムのデータに基づき面積が1になるようにスムーズな分布を推定する手法である。ヒストグラムとカーネル密度関数を重ねてプロットすることもできる。
次の構文となる。
<書き方1>
df1.plot.kde(y='列ラベル')
<書き方2>
df1.plot(y='列ラベル', kind='kde')
y:縦軸に使う列ラベル(文字列、複数指定する場合はリスト)横軸は自動で設定されるため
xは指定する必要はない
この場合,df1にある全ての列がヒストグラムとして重ねて表示される。特定の列だけを使う場合は列を選択してplot()を使う。
df1.plot.kde(y=['X','Z'])
pass
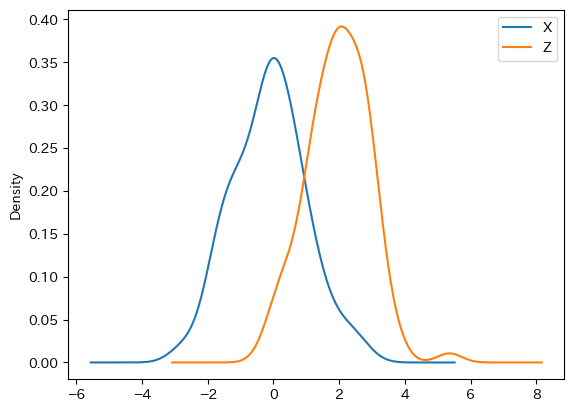
<基本的な引数>
様々な引数があり図に「飾り付け」をすることができる。詳しくはこのリンクを参照することにして,ここでは基本的な引数だけを紹介する。
title:図のタイトル(文字列型で指定)linestyle又はstyle:線のスタイル(リストにして列の順番で指定する;-,--,-.,:)linewidthorlw:線の幅color:色(リストにして列の順番で指定する; 参照サイト)rは赤kは黒gはグリーン
alpha:透明度(0から1.0; デフォルトは1)fontsize:横軸・縦軸の数字のフォントサイズの設定figsize:図の大きさfigsize=(キャンバスの横幅、キャンバスの縦の長さ)
legend:凡例の表示を指定DataFrameの場合はデフォルトはTrueSeriesの場合はデフォルトはFalse
label:凡例の表現を指定(Seriesのみ有効)grid:グリッド表示(ブール型;デフォルトはFalse)ax:プロットする「軸」を指定する。
引数を指定してXをプロットしてみる。
df1.plot.kde(y='X',
title='タイトルです',
linewidth=5,
linestyle='-.',
color='red',
alpha=0.5,
fontsize=20,
figsize=(8,4),
legend=True,
label='Xの凡例',
grid=True
)
pass
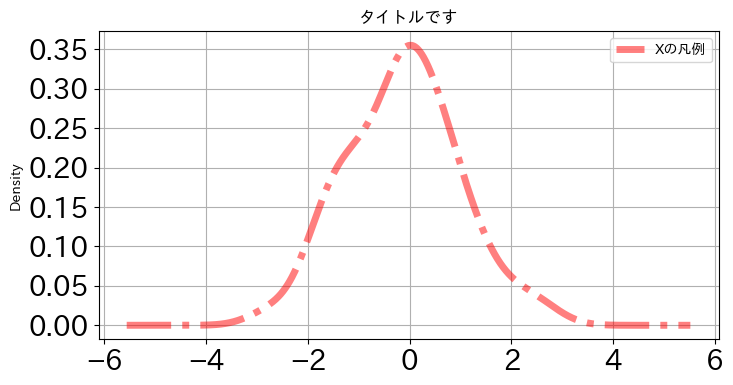
この図ではタイトルと横軸・縦軸ラベルの大きさが調整できていないが,上で説明したタイトルとラベルのサイズの調整のコードと共通なのでそちらを参照しよう。
次にヒストグラムとカーネル密度推定プロットを重ねて図示してみる。ここで重要な点がヒストグラムに引数density=Trueを設定することである。これがないと縦軸の単位が異なり上手く表示できない。
ax_ = df1.plot.hist(y='X',
label='Xのヒストグラム',
density=True)
df1.plot.kde(y='X',
label='XのKDE',
ax=ax_)
ax_.legend()
pass
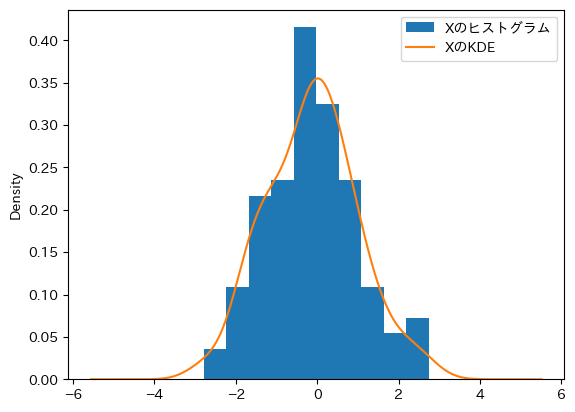
縦線・横線#
図に縦線や横線を追加したい場合がある。その場合は,タイトルとラベルのサイズの調整にあるように「軸」に追加していく事になる。次のような書き方となる。
縦線の場合
ax_.axvline(<横軸の値>)
ここで`axvline`の`ax`はAXis,`v`はVertical,`line`はLINEのことを表している。横線の場合
ax_.axhline(<縦軸の値>)
ここで`axhline`の`ax`はAXis,`h`はHorizontal,`line`はLINEのことを表している。
ここでax_は.plot()で返された「軸」のことである。
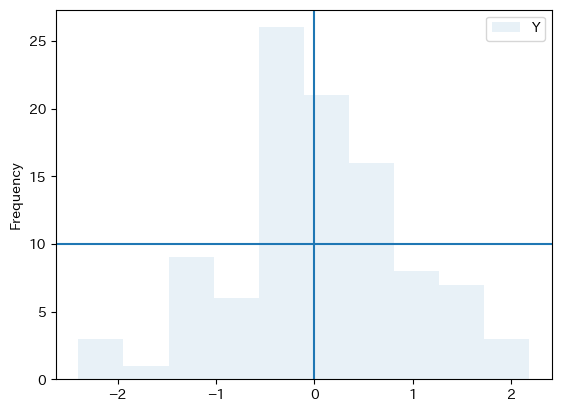
Yのヒストグラムを使ってプロットしてみよう。
ax_ = df1.plot.hist(y='Y', alpha=0.1)
ax_.axvline(0)
ax_.axhline(10)
pass
<基本的な引数>
様々な引数があり図に「飾り付け」をすることができる。詳しくはこのリンクとこのリンクを参照することにして,ここでは基本的な引数だけを紹介する。
ymin:axvlineの縦軸における最小値(0~1の値; デフォルト0)ymax:axvlineの縦軸における最大値(0~1の値; デフォルト1)xmin:axhlineの横軸における最小値(0~1の値; デフォルト0)xmax:axhlineの横軸における最大値(0~1の値; デフォルト1)linestyle:線のスタイル(リストにして列の順番で指定する;----.:)linewidthorlw:線の幅color:色(リストにして列の順番で指定する; 参照サイト)rは赤kは黒gはグリーン
alpha:透明度(0から1.0; デフォルトは1)
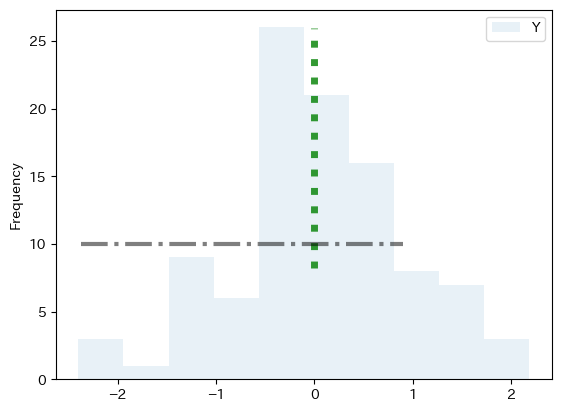
引数を指定してプロットしてみる。
ax_ = df1.plot.hist(y='Y', alpha=0.1)
ax_.axvline(0,
ymin=0.3,
ymax=0.95,
linestyle=':',
linewidth=5,
color='g',
alpha=0.8)
ax_.axhline(10,
xmin=0.05,
xmax=0.7,
linestyle='-.',
linewidth=3,
color='k',
alpha=0.5)
pass
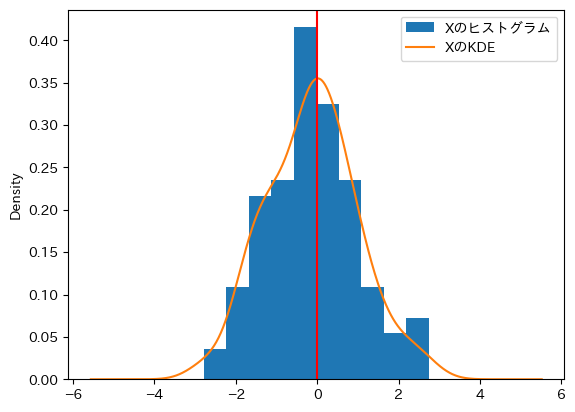
最後に上のヒストグラムとカーネル密度推定プロットに縦線を加えてみよう。
ax_ = df1.plot.hist(y='X',
label='Xのヒストグラム',
density=True)
df1.plot.kde(y='X',
label='XのKDE',
ax=ax_)
ax_.legend()
ax_.axvline(0, color='red')
pass
棒グラフ#
まず次のコードでデータを準備しよう。
df2 = pd.DataFrame({'country':['A','B','C'],
'gdp':[100,90,110],
'con':[50,60,55],
'inv':[15,10,20],
'gov':[10,5,30],
'netex':[25,15,5]})
3国のGDPとその構成要素からなるDataFrameである。
country:国gdp:GDPcon:消費inv:投資gov:政府支出netex:純輸出
このDataFrameを使って棒グラフの作成方法を説明するが,次の構文となる。
<書き方1>
df2.plot.bar(x='列ラベル', y='列ラベル')
<書き方2>
df2.plot(x='列ラベル', y='列ラベル', kind='bar')
x:横軸に使う列ラベル(文字列)y:縦軸に使う列ラベル(文字列、複数の場合はリスト)
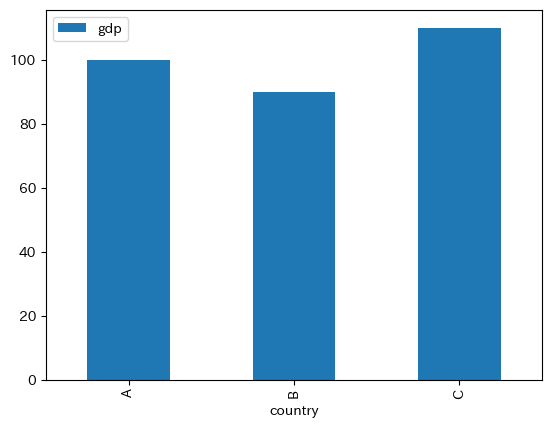
まずA国のgdpの棒グラフを表示してみよう。
df2.plot.bar(x='country', y='gdp')
pass
複数の棒(データ)を並べたい場合もあるだろう。その場合は引数yにリストを指定すれば表示できる。
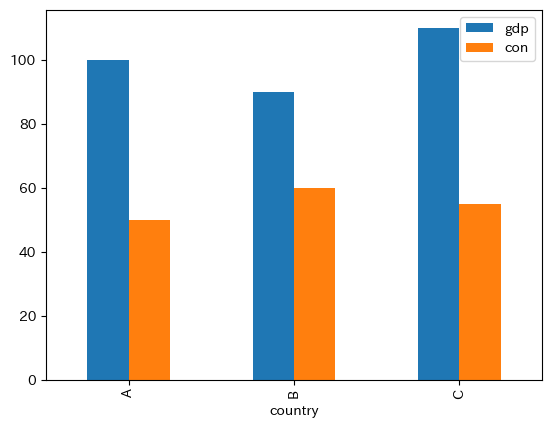
df2.plot.bar(x='country', y=['gdp','con'])
pass
<基本的な引数>
詳しい引数についての説明はこのリンクを参照することにして,ここでは基本的な引数だけを紹介する。
color:色(リストにして列の順番で指定する; 参照サイト)r又はred:赤k又はblack:黒g又はgreen:グリーン
stacked:(ブール型;デフォルトはFalse)複数データを使う場合に棒を積み上げるかどうかを指定
fontsize:横軸・縦軸の数字のフォントサイズの設定figsize:図の大きさfigsize=(キャンバスの横幅、キャンバスの縦の長さ)
legend:凡例の表示を指定DataFrameの場合はデフォルトはTrue
label:凡例の表現を指定grid:グリッド表示(ブール型;デフォルトはFalse)rot(rotationの略):横軸の変数の表示の角度(デフォルトは90)subplots:複数の図をプロットする(詳細はライン・プロットを参照)ax:プロットする「軸」を指定する。
これらの引数を使いプロットしてみよう。
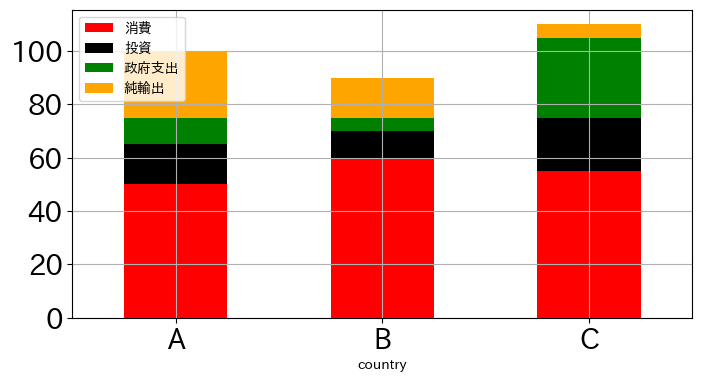
df2.plot.bar(x='country', y=['con','inv','gov','netex'],
color=['red','black','green','orange'],
stacked=True,
fontsize=20,
figsize=(8,4),
# legend=False,
label=['消費','投資','政府支出','純輸出'],
grid=True,
rot=0
)
pass
次に,ライン・プロットを追加する例を考えてみよう。df2には列gdpがあり,それを表すライン・プロットを重ねることにしよう。
ax_ = df2.plot.bar(x='country', y=['con','inv','gov','netex'],
stacked=True,
fontsize=15,
label=['消費','投資','政府支出','純輸出'],
rot=0)
df2.plot(x='country', y='gdp',
color='black',
marker='o',
legend=True,
label='国内総生産',
ax=ax_)
ax_.set_title('3カ国のGDPと構成要素', size=20)
ax_.set_xlabel('国', size=15)
ax_.set_ylabel('単位:億米ドル', size=15)
pass
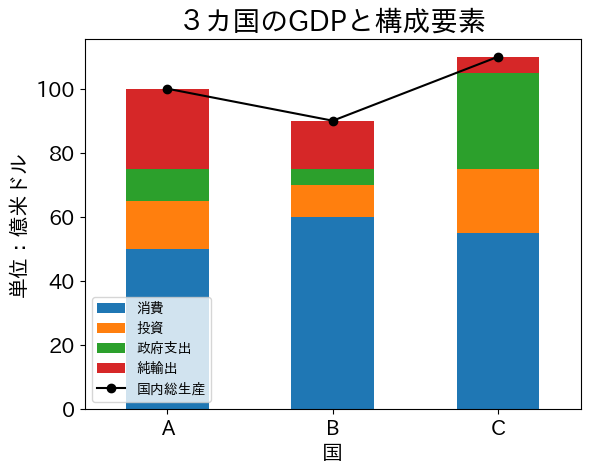
棒の高さとGDPのマーカーの高さは同じであることがわかる。